Das Q-Learning (auf Spanisch Aprendizaje Q) hat sich von den ersten Verhaltensversuchen wie dem Pawlowschen klassischen Konditionieren, bis hin zu einer der wichtigsten Techniken im Bereich des Machine Learning (maschinelles Lernen) weiterentwickelt. Im Folgenden untersuchen wir seine Entwicklung und seine Anwendung in der Neurorehabilitation und kognitiven Stimulation.
Die Pawlowschen Experimente
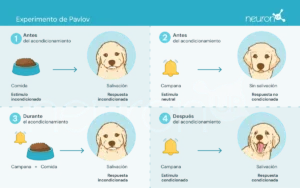
Ivan Pawlow, ein russischer Physiologe des späten 19. Jahrhunderts, ist dafür bekannt, die Grundlagen der Verhaltenspsychologie durch seine Experimente zum klassischen Konditionieren zu legen. In diesen Experimenten zeigte Pawlow, dass Hunde lernen können, einen neutralen Reiz, wie den Klang einer Glocke, mit einem unbedingten Reiz, wie Futter, zu verknüpfen, wodurch eine unbedingte Reaktion ausgelöst wird: Speichelfluss.

Dieses Experiment war grundlegend, um zu zeigen, dass Verhalten durch Assoziation erworben werden kann – ein entscheidendes Konzept, das später die Entwicklung der Theorien des Verstärkungslernens prägte.
Theorien des Verstärkungslernens
Diese Theorien befassen sich damit, wie Menschen und Tiere Verhaltensweisen anhand der Konsequenzen ihrer Handlungen erlernen, was für die Entwicklung von Algorithmen wie Q-Learning entscheidend war.
Es gibt einige Schlüsselkonzepte, mit denen wir uns vertraut machen sollten, bevor wir fortfahren:
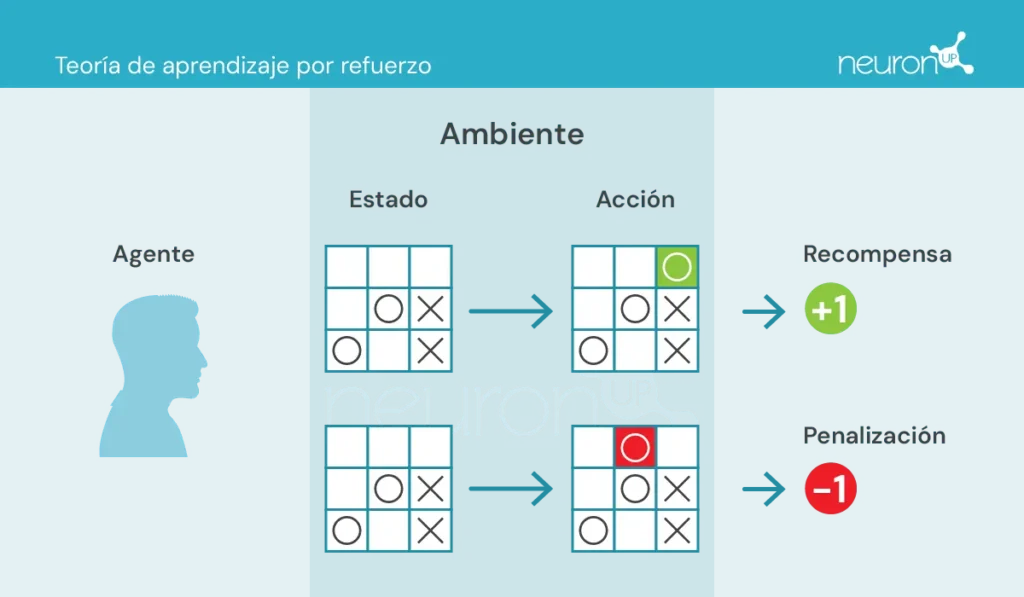
- Agent: zuständig für das Ausführen der Aktion.
- Umgebung: Umfeld, in dem der Agent sich bewegt und interagiert.
- Zustand: aktuelle Situation der Umgebung.
- Aktion: mögliche Entscheidungen, die der Agent trifft.
- Belohnung: Prämien, die dem Agenten zugewiesen werden.
In dieser Art des Lernens führt ein Agent Aktionen in der Umgebung aus, erhält Informationen in Form von Belohnungen/Bestrafungen und nutzt diese, um sein Verhalten im Laufe der Zeit anzupassen.
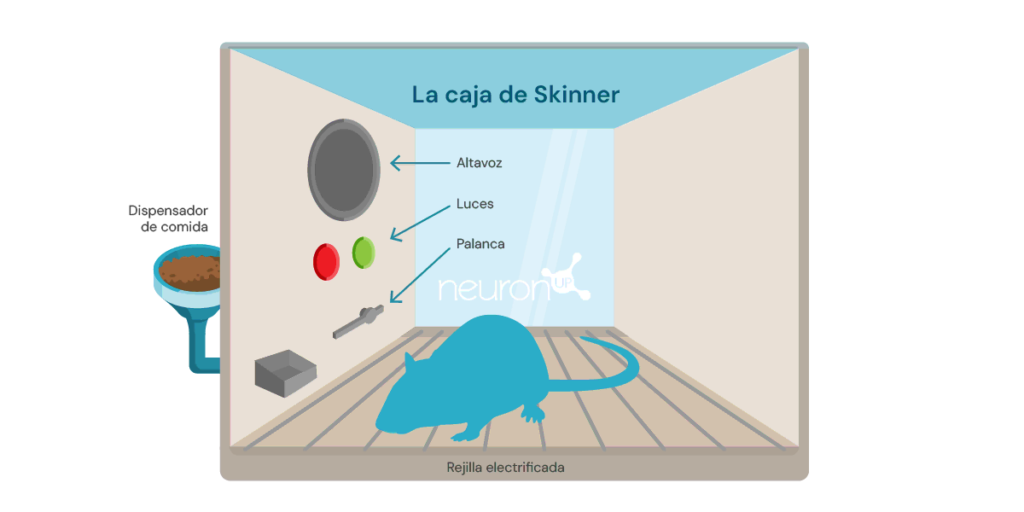
Ein klassisches Experiment des Verstärkungslernens ist das Experiment der Skinner-Box, durchgeführt vom amerikanischen Psychologen Burrhus Frederic Skinner im Jahr 1938. In diesem Experiment zeigte Skinner, dass Ratten lernen können, einen Hebel zu drücken, um Futter zu erhalten, und dabei positive Verstärkung als Mittel zur Verhaltensformung nutzen.
Das Experiment besteht darin, eine Ratte in eine Box zu setzen, die einen Hebel zum Drücken, einen Futterspender und gelegentlich eine Lampe und einen Lautsprecher enthält.
Jedes Mal, wenn die Ratte den Hebel betätigt, wird ein Futterkorn im Spender freigegeben. Das Futter wirkt als positive Verstärkung, eine Belohnung für das Betätigen des Hebels. Mit der Zeit wird die Ratte den Hebel häufiger betätigen, was zeigt, dass sie das Verhalten durch Verstärkung erlernt hat.
Diese Art des Lernens diente als Grundlage für Algorithmen des Machine Learning, wie Q-Learning, die es Maschinen ermöglichen, optimale Verhaltensweisen autonom mittels Versuch und Irrtum zu erlernen.
Was ist Q-Learning?
Q-Learning wurde 1989 von Christopher Watkins als Algorithmus des Verstärkungslernens eingeführt. Dieser Algorithmus ermöglicht einem Agenten, den Wert von Handlungen in einem bestimmten Zustand zu erlernen, indem er sein Wissen durch Erfahrung kontinuierlich aktualisiert, ähnlich wie die Ratte in der Skinner-Box.
Im Gegensatz zu den Pawlowschen Experimenten, bei denen das Lernen auf einfachen Assoziationen basierte, verwendet Q-Learning eine komplexere Methode des Versuch und Irrtums. Der Agent erkundet verschiedene Aktionen und aktualisiert eine Q-Tabelle, in der die Q-Werte gespeichert sind, die die erwarteten zukünftigen Belohnungen für die beste Aktion in einem bestimmten Zustand darstellen.
Q-Learning wird in verschiedenen Bereichen angewendet, zum Beispiel in Empfehlungssystemen (wie von Netflix oder Spotify), in autonomen Fahrzeugen (wie Drohnen oder Robotern) und in der Ressourcenoptimierung. Im Folgenden untersuchen wir, wie diese Technologie in der Neurorehabilitation eingesetzt werden kann.
Q-Learning und NeuronUP
Ein Vorteil von NeuronUP ist die Möglichkeit, die Aktivitäten an die spezifischen Bedürfnisse jedes Nutzers anzupassen. Allerdings kann die Personalisierung jeder einzelnen Aktivität aufgrund der Vielzahl an anzupassenden Parametern mühsam sein.
Q-Learning ermöglicht die Automatisierung dieses Prozesses, indem die Parameter basierend auf der Leistung des Nutzers in den verschiedenen Aktivitäten angepasst werden. Dadurch wird sichergestellt, dass die Übungen herausfordernd, aber erreichbar sind, was die Effektivität und Motivation während der Rehabilitation verbessert.
Wie funktioniert es?
In diesem Kontext lernt der Agent, der mit einem Nutzer verglichen werden kann, der mit einer Aktivität interagiert, in verschiedenen Situationen optimale Entscheidungen zu treffen, um die Aktivität erfolgreich zu bewältigen.
Q-Learning ermöglicht es dem Agenten, verschiedene Aktionen auszuprobieren, indem er mit seiner Umgebung interagiert, Belohnungen oder Bestrafungen erhält und eine Q-Tabelle aktualisiert, die diese Q-Werte speichert. Diese Werte repräsentieren die erwarteten zukünftigen Belohnungen, die durch das Treffen der besten Aktion in einem bestimmten Zustand erzielt werden können.
Die Q-Learning-Aktualisierungsregel lautet wie folgt:
\[Q(s,a) \leftarrow Q(s,a) + \alpha\bigl(r + \gamma \cdot \max_{a‘}\bigl(Q(s‘,a‘)\bigr) – Q(s,a)\bigr)\]Dabei gilt:
𝛂 – ist die Lernrate.
r – die Belohnung, die nach Ausführen der Aktion a im Zustand s erhalten wird.
𝛄 – ist der Abzinsungsfaktor, der die Bedeutung zukünftiger Belohnungen darstellt.
s’ – ist der Folgezustand.
\(\max_{a‘}\bigl(Q(s‘,a‘)\bigr)\) – ist der maximale Q-Wert für den Folgezustand s’.

Melden Sie sich
für unseren
Newsletter an
Anwendungsbeispiel in einer NeuronUP-Aktivität
Nehmen wir die NeuronUP-Aktivität „Imágenes revueltas“, die Fähigkeiten wie Planung, visuell-konstruktive Fähigkeiten und räumliche Beziehung fördert. Bei dieser Aktivität besteht das Ziel darin, ein Puzzle zu lösen, das gemischt und in Teile zerschnitten wurde.
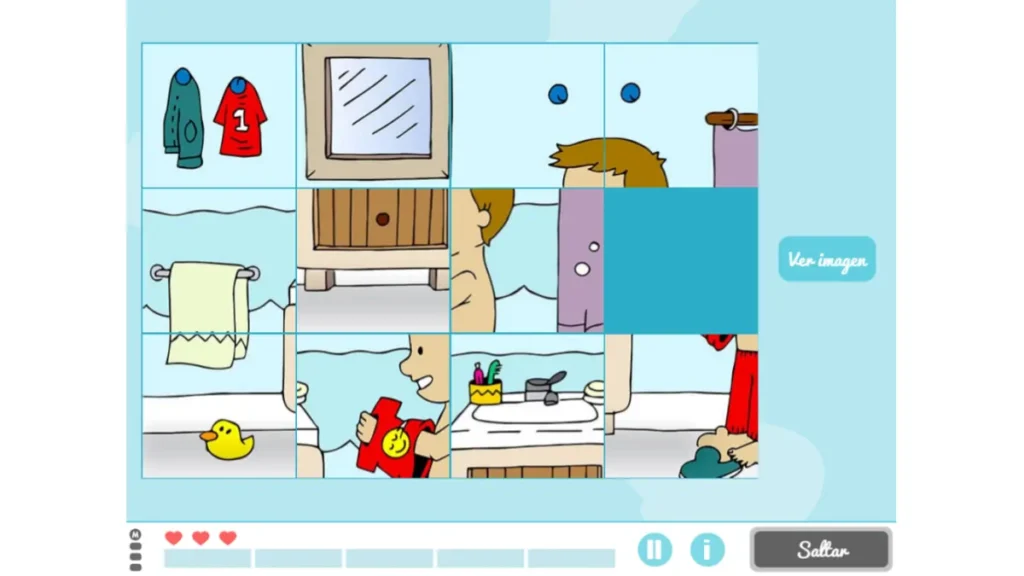
Die Variablen, die die Schwierigkeit dieser Aktivität bestimmen, sind die Matrizengröße (Anzahl der Zeilen und Spalten) sowie der Unordnungsgrad der Teile (niedrig, mittel, hoch oder sehr hoch).
Um den Agenten darauf zu trainieren, das Puzzle zu lösen, wurde eine Belohnungsmatrix erstellt, die auf der minimalen Anzahl an Zügen basiert, die zur Lösung erforderlich sind und durch folgende Formel definiert wird:
\[\mathrm{Min\_Attempts} \;=\;\left\lceil \frac{\mathrm{factor} * \mathrm{rows} * \mathrm{columns}}{5}\right\rceil,\quad \mathrm{factor}\in\{1,3,5,7\}\]Der Faktor hängt vom Unordnungsgrad ab. Sobald die Matrix erstellt war, wurde ein Q-Learning-Algorithmus eingesetzt, um den Agenten automatisch beim Lösen des Puzzles zu trainieren.
Diese Integration umfasst:
- Q-Wert-Abruf: Die Funktion ruft den Q-Wert für ein Zustands-Aktions-Paar aus der Q-Tabelle ab. Wenn das Paar zuvor nicht trainiert wurde, gibt sie 0 zurück. Diese Funktion ermittelt die erwartete Belohnung für das Ausführen einer bestimmten Aktion in einem bestimmten Zustand.
- Q-Wert-Aktualisierung: Die Funktion aktualisiert den Q-Wert für ein Zustands-Aktions-Paar basierend auf der erhaltenen Belohnung und dem maximalen Q-Wert des Folgezustands. Diese Funktion implementiert die zuvor erwähnte Q-Learning-Aktualisierungsregel.
- Entscheidung über die auszuführende Aktion: Die Funktion entscheidet, welche Aktion in einem gegebenen Zustand ausgeführt werden soll, und verwendet eine Epsilon-Greedy-Strategie. Diese Strategie balanciert Exploration und Exploitation:
- Exploration: Hierbei wird mit einer Wahrscheinlichkeit ε (Explorationsrate, ein Wert zwischen 0 und 1, der die Wahrscheinlichkeit bestimmt, neue Aktionen statt bekannter Aktionen zu erkunden) eine zufällige Aktion ausgewählt, um dem Agenten die Entdeckung potenziell besserer Aktionen zu ermöglichen.
- Exploitation: Hierbei werden mit einer Wahrscheinlichkeit 1−ε die Aktionen mit dem höchsten Q-Wert für den aktuellen Zustand ausgewählt, um zu prüfen, ob sie in Zukunft bessere Belohnungen bieten könnten. Der Agent nutzt sein erlerntes Wissen: a‘ = argmax_a Q(s,a). Dabei ist a’ die Aktion, die die Q-Funktion in einem Zustand s maximiert. Das bedeutet, dass für einen Zustand s die Aktion a mit dem höchsten Q-Wert ausgewählt wird.
Diese Funktionen arbeiten zusammen, damit der Q-Learning-Algorithmus eine optimale Strategie zur Lösung des Puzzles entwickeln kann.
Vorläufige Analyse der Algorithmusausführung
Der Algorithmus wurde auf ein Puzzle mit einer 2×3-Matrix und einem Schwierigkeitsfaktor von 1 (niedrig) angewandt, was einer minimalen Anzahl von 2 Versuchen entspricht. Der Algorithmus wurde 20-mal auf demselben Puzzle mit derselben Mischkonfiguration ausgeführt und nach jedem Schritt die Q-Tabelle aktualisiert. Nach 20 Durchläufen wurde das Puzzle in einer anderen Konfiguration gemischt und der Prozess wiederholt, was insgesamt 2000 Iterationen ergab. Die Anfangswerte der Parameter waren:
- Belohnung für das Lösen des Puzzles: 100 Punkte
- Bestrafung für jeden Zug: −1 Punkt
In jedem Schritt wurde basierend auf der Anzahl korrekt platzierter Teile eine zusätzliche Belohnung oder Bestrafung angewendet, um dem Agenten seinen Fortschritt bei der Lösung des Puzzles zu verdeutlichen. Dies wurde mit folgender Formel berechnet:
\[W \times \bigl(N_{\mathrm{correct}}^i \;−\; N_{\mathrm{correct}}^{\,i-1}\bigr)\]Dabei gilt:
- W ist der Gewichtungsfaktor.
- \(N_{\mathrm{correct}}^{\,i}\) ist die Anzahl der korrekten Teile nach dem Zug.
- \(N_{\mathrm{correct}}^{\,i-1}\) ist die Anzahl der korrekten Teile vor dem Zug.
Die folgende Grafik zeigt die für jede Iteration benötigte Zuganzahl, damit das Modell ein 2×3-Puzzle löst. Zu Beginn benötigt das Modell eine hohe Anzahl an Zügen, was seinen Mangel an Wissen über eine effiziente Lösung widerspiegelt. Mit zunehmendem Training des Q-Learning-Algorithmus ist jedoch ein Abwärtstrend bei der Zuganzahl zu beobachten, was darauf hindeutet, dass das Modell lernt, seinen Lösungsprozess zu optimieren.
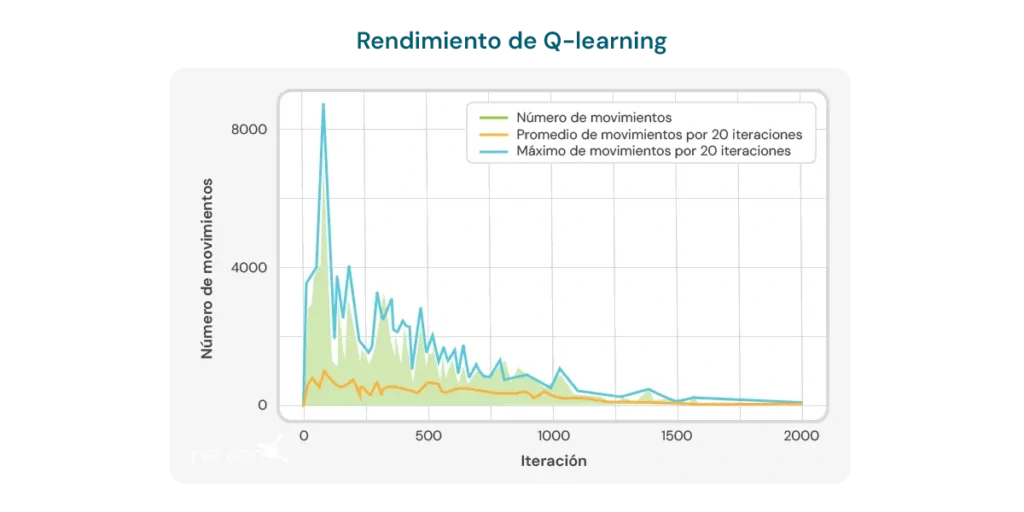

Dieser Trend ist ein positives Indiz für das Potenzial des Algorithmus, sich im Laufe der Zeit zu verbessern. Es müssen jedoch mehrere wichtige Einschränkungen berücksichtigt werden:
- Spezifische Puzzlegröße: Der Algorithmus erweist sich hauptsächlich bei Puzzles mit einer bestimmten Größe, wie z. B. einer 2×3-Matrix, als effektiv. Bei Änderung der Größe oder Komplexität des Puzzles kann die Leistung des Algorithmus deutlich abnehmen.
- Rechenzeit: Wenn der Algorithmus auf andere oder komplexere Konfigurationen angewendet wird, steigt die für Berechnungen und die Lösung des Puzzles benötigte Zeit erheblich an. Dies begrenzt seine Anwendbarkeit in Situationen, die schnelle Antworten erfordern, oder bei besonders komplexen Puzzles.
- Relativ hohe Zuganzahl: Trotz der beobachteten Verbesserung bleibt die für die Lösung des Puzzles erforderliche Zuganzahl relativ hoch, selbst nach mehreren Iterationen. In den letzten Durchläufen benötigt das Modell im Durchschnitt 8 bis 10 Züge, was darauf hinweist, dass noch Raum zur Verbesserung der Lerneffizienz besteht.
Diese Einschränkungen unterstreichen die Notwendigkeit einer weiteren Verfeinerung des Algorithmus, sei es durch Anpassung der Lernparameter, Verbesserung der Modellstruktur oder Integration ergänzender Techniken, die ein effizienteres und anpassungsfähigeres Lernen für verschiedene Puzzlekonfigurationen ermöglichen. Trotz dieser Einschränkungen sollten wir die Vorteile von Q-Learning in der Neurorehabilitation nicht aus den Augen verlieren, darunter:
- Dynamische Anpassung der Aktivitäten: Q-Learning ist in der Lage, die Parameter therapeutischer Aktivitäten automatisch basierend auf der individuellen Leistung des Nutzers anzupassen. Dies bedeutet, dass die Aktivitäten in Echtzeit personalisiert werden können, sodass jeder Nutzer auf einem herausfordernden, aber erreichbaren Niveau arbeiten kann. Dies ist besonders in der Neurorehabilitation nützlich, wo die Fähigkeiten der Nutzer stark variieren und sich im Laufe der Zeit verändern können.
- Erhöhte Motivation und Engagement: Da die Aktivitäten ständig an das Fähigkeitsniveau des Nutzers angepasst werden, wird Frustration bei zu schwierigen Aufgaben oder Langeweile bei zu einfachen Aufgaben vermieden. Dies kann die Motivation und das Engagement des Nutzers im Rehabilitationsprogramm erheblich steigern, was entscheidend für den Erfolg ist.
- Optimierung des Lernprozesses: Durch den Einsatz von Q-Learning kann das System aus den bisherigen Interaktionen des Nutzers mit den Aktivitäten lernen und dadurch den Lern- und Rehabilitationsprozess optimieren. Dies ermöglicht effektivere Übungen, da der Fokus auf Bereichen liegt, in denen der Nutzer mehr Unterstützung benötigt, und verkürzt die Zeit, um therapeutische Ziele zu erreichen.
- Effizienz bei klinischen Entscheidungen: Fachkräfte können von Q-Learning profitieren, indem sie datenbasierte Empfehlungen erhalten, wie Therapien angepasst werden sollten. Dies erleichtert fundiertere und präzisere klinische Entscheidungen, was wiederum die Qualität der Betreuung des Nutzers verbessert.
- Kontinuierliche Verbesserung: Im Laufe der Zeit kann das auf Q-Learning basierende System seine Leistung durch die Ansammlung von Daten und Nutzererfahrung verbessern. Das bedeutet, dass das System mit zunehmender Nutzung immer effektiver in der Personalisierung und Optimierung von Übungen wird, was langfristig einen Vorteil im Neurorehabilitationsprozess bietet.
Abschließend hat sich Q-Learning von seinen Wurzeln in der Verhaltenspsychologie zu einem leistungsstarken Werkzeug in der künstlichen Intelligenz und Neurorehabilitation entwickelt. Seine Fähigkeit, Aktivitäten autonom anzupassen, macht es zu einer wertvollen Ressource, um die Effektivität von Rehabilitationstherapien zu verbessern, auch wenn weiterhin Herausforderungen bestehen, um seine Anwendung vollständig zu optimieren.
Literaturverzeichnis
- Bermejo Fernández, E. (2017). Aplicación de algoritmos de reinforcement learning a juegos.
- Giró Gràcia, X., & Sancho Gil, J. M. (2022). La Inteligencia Artificial en la educación: Big data, cajas negras y solucionismo tecnológico.
- Meyn, S. (2023). Stability of Q-learning through design and optimism. arXiv preprint arXiv:2307.02632.
- Morinigo, C., & Fenner, I. (2021). Teorías del aprendizaje. Minerva Magazine of Science, 9(2), 1-36.
- M.-V. Aponte, G. Levieux und S. Natkin. (2009). Measuring the level of difficulty in single player video games. Entertainment Computing.
- P. Jan L., H. Bruce D., P. Shashank, B. Corinne J., & M. Andrew P. (2019). The Effect of Adaptive Difficulty Adjustment on the Effectiveness of a Game to Develop Executive Function Skills for Learners of Different Ages. Cognitive Development, pp. 49, 56–67.
- R. Anna N., Z. Matei & G. Thomas L. Optimally Designing Games for Cognitive Science Research. Computer Science Division and Department of Psychology, University of California, Berkeley.
- Toledo Sánchez, M. (2024). Aplicaciones del aprendizaje por refuerzo en videojuegos.
Wenn Ihnen dieser Artikel über Q-Learning gefallen hat, könnten Sie auch an diesen Artikeln von NeuronUP interessiert sein:





Dieser Artikel wurde übersetzt; Link zum Originalartikel auf Spanisch:
Q-learning: Desde los experimentos de Pavlov a la neurorrehabilitación moderna
 Die Wettkämpfe der Paralympischen Spiele 2024 und die Bedeutung der psychischen Gesundheit
Die Wettkämpfe der Paralympischen Spiele 2024 und die Bedeutung der psychischen Gesundheit

Schreiben Sie einen Kommentar