
Elina Filatova, Data Scientist di NeuronUP, spiega in questo articolo come il modello Time-Aware LSTM (TA-LSTM) permette di prevedere con alta precisione i risultati degli utenti anche quando i loro dati vengono generati in modo irregolare.
In NeuronUP implementiamo attivamente i metodi più avanzati di apprendimento automatico che ci permettono di prevedere con alta precisione il comportamento degli utenti, identificare tendenze e prevedere risultati futuri basandoci sui loro dati storici.
Tuttavia, gli approcci tradizionali all’apprendimento automatico incontrano difficoltà quando i dati vengono generati in modo irregolare e gli intervalli tra le osservazioni sono caotici o specifici per ciascun utente. In tali casi, i modelli convenzionali diventano inefficaci, poiché non tengono conto del ritmo e della frequenza unici dell’attività di ciascuna persona.
Proprio per risolvere questo problema utilizziamo una versione speciale della rete neurale LSTM, chiamata Time-Aware LSTM (TA-LSTM). Questo modello è in grado di considerare efficacemente gli intervalli temporali tra gli eventi, permettendo di prevedere serie temporali anche quando i dati sono irregolari.
Obiettivo dello studio e principali difficoltà
In NeuronUP disponiamo di metriche dell’utente provenienti dai giorni precedenti, con l’obiettivo di prevedere i loro risultati la prossima volta che svolgeranno l’attività. A prima vista, questo potrebbe sembrare un compito semplice, ma nella pratica reale emergono diverse difficoltà importanti:
- Ritmo individuale degli utenti: Ogni utente ha un modello di allenamento unico; alcuni giocano quotidianamente, altri settimanalmente, e alcuni possono fare pause prolungate fino a un mese, tornando inaspettatamente alle attività. Per esempio, Alex si allena in modo costante ogni giorno, mentre José preferisce intervalli settimanali. Se si media i loro risultati senza considerare questa frequenza, si perderanno dettagli cruciali.
- Varietà di attività e il loro impatto differenziale sugli utenti: Le attività in NeuronUP sono progettate per migliorare diverse funzioni cognitive come la memoria, l’attenzione e la logica, tra le altre. Ogni attività possiede un livello di difficoltà particolare che varia a seconda dell’utente. Ciò che risulta semplice per una persona potrebbe rappresentare una grande sfida per un’altra.
- Approccio su attività specifiche: Gli specialisti di NeuronUP determinano quali attività assegnare a ciascun utente. Ad esempio, Carmen esegue regolarmente esercizi di memoria, logica e matematica, mentre Pablo preferisce esclusivamente esercizi di attenzione. Pertanto, il modello predittivo deve considerare il percorso personalizzato di ogni giocatore.
Ovviamente, tutti questi dettagli complicano sia il corretto processo di preparazione dei dati sia il training dei modelli di apprendimento automatico. Ignorare il ritmo individuale dei giocatori, i loro intervalli irregolari e i diversi livelli di difficoltà delle attività conduce inevitabilmente alla perdita di informazioni chiave. Di conseguenza, esiste il rischio di ottenere previsioni meno accurate, il che a sua volta può ridurre l’efficacia delle raccomandazioni personalizzate in NeuronUP.

Iscriviti
alla nostra
Newsletter
Soluzione: Time-Aware LSTM
Per superare efficacemente tutte le difficoltà menzionate in precedenza, il team di dati di NeuronUP ha sviluppato una soluzione specifica basata sul modello personalizzato Time-Aware LSTM (TA-LSTM). Si tratta di una versione migliorata della rete neurale LSTM standard, in grado di considerare non solo gli eventi nelle serie temporali, ma anche gli intervalli di tempo tra di essi.
Preparazione dei dati: perché la differenza temporale è così importante?
Il nostro modello riceve in input dati preparati in modo specifico. Ogni record è una matrice bidimensionale che contiene i risultati sequenziali di un giocatore, ordinati cronologicamente, nonché gli intervalli di tempo in giorni tra ogni volta che ha svolto l’attività. Per capire perché è così importante considerare la differenza temporale, conosciamo due personaggi che ci aiuteranno a illustrare chiaramente questo punto.
Immaginiamo una maratona chiamata “Il più veloce e agile”, per la quale si stanno preparando due atleti:
- Neuronito – uno sportivo disciplinato e determinato. Non salta mai un allenamento, si allena ogni giorno e cura meticulosamente la sua alimentazione. Neuronito progredisce costantemente: con ogni nuova sessione di allenamento diventa più veloce, resistente e sicuro di sé. Data la sua preparazione regolare, possiamo prevedere facilmente che avrà un’eccellente prestazione nella maratona.

- Lentonito – un atleta talentuoso, ma meno disciplinato. I suoi allenamenti sono irregolari. Oggi si allena con entusiasmo, ma domani preferisce riposare gustando una paella e un buon prosciutto. Queste sessioni incostanti generano fluttuazioni nelle sue prestazioni: a volte migliora, altre volte no, ma senza una crescita stabile. È probabile che Lentonito arrivi al traguardo con risultati meno impressionanti.

In questo modo abbiamo visto con un esempio semplice quanto influenzino gli intervalli di tempo tra gli eventi sui risultati finali. Proprio queste informazioni sulla stabilità e regolarità negli “allenamenti” sono quelle che forniamo al nostro modello.
Se non considerassimo gli intervalli di tempo, il modello percepirebbe questi due atleti come uguali, senza notare la differenza nel loro approccio di allenamento. Ma TA-LSTM rileva questa caratteristica chiave, analizza gli intervalli individuali tra gli eventi e produce previsioni più precise, tenendo conto del ritmo unico di ciascun partecipante (o, nel nostro caso in NeuronUP, dell’utente).
Ma non è tutto! Come avrai notato, abbiamo anche menzionato l’alimentazione di Neuronito e Lentonito. Non a caso, ma perché questi dati rappresentano caratteristiche aggiuntive che influenzano anch’esse significativamente il risultato finale.
Allo stesso modo, il nostro modello è in grado di considerare non solo gli intervalli di tempo, ma anche altre caratteristiche importanti, come l’età, il genere, la diagnosi e persino le preferenze degli utenti.
Ciò permette di migliorare considerevolmente la precisione delle previsioni, proprio come nel nostro esempio con i protagonisti, in cui abbiamo preso in considerazione il loro regime alimentare e la sua influenza sul successo.
Dettagli tecnici
Ora che abbiamo visto il concetto principale, passiamo all’aspetto tecnico del funzionamento del modello Time-Aware LSTM (TA-LSTM). Questo modello è una modifica della cella LSTM standard, progettata specificamente per tenere in considerazione gli intervalli di tempo tra eventi sequenziali.
L’obiettivo principale di TA-LSTM è l’aggiornamento adattivo dello stato di memoria interno del modello in base al tempo trascorso dall’ultima osservazione. Questo approccio è cruciale quando si lavora con serie temporali irregolari, esattamente il tipo di dati con cui lavoriamo in NeuronUP.
Il vettore di input all’istante di tempo t è rappresentato come:
[\text{inputs}_{t} = [x_{t},\,\Delta t]]Dove:
- \(x_t \in \mathbb{R}^d\) – è il vettore di caratteristiche che descrive l’evento attuale (ogni giorno in cui viene svolta l’attività).
- \(\Delta t \in \mathbb{R}\) – è l’intervallo di tempo tra l’osservazione attuale e la precedente.
Gli stati precedenti del modello sono rappresentati nel modo standard:
[h_{t-1},\; C_{t-1}]Dove:
- \(h_{t-1}\) – è il vettore di stato nascosto al passo precedente.
- \(C_{t-1}\) – è lo stato di memoria (cella LSTM) al passo precedente.
Per tenere conto dell’influenza dell’intervallo di tempo t, il modello utilizza un meccanismo speciale di attenuazione della memoria, descritto dalla seguente formula:
[\gamma_t = e^{-\text{RELU}(w_d \cdot \Delta t + b_d)}]Dove:
- \(w_d, \; b_d\) – sono parametri addestrabili del modello.
- \(\text{RELU}(x) = \max(0, x)\) – è la funzione di attivazione che evita valori negativi.
Il coefficiente di attenuazione \(\gamma_t\) controlla l’aggiornamento dello stato di memoria.
L’aggiornamento della memoria è definito come:
[\bar{C}_{t-1} = \gamma_t \cdot C_{t-1}]Ciò significa che quando l’intervallo di tempo Δt aumenta, il valore di γ_t tende a zero, provocando un maggiore “dimenticamento” degli stati di memoria precedenti.
Nel passaggio successivo, lo stato di memoria corretto \(\bar{C}_{t-1}\) viene introdotto nelle equazioni standard di LSTM:
[h_t, \; C_t = \text{LSTM}(x_{t’}, h_{t-1}, \bar{C}_{t-1})]I valori di output \(h_t\) e lo stato di memoria aggiornato \(C_t\) vengono utilizzati nel passaggio successivo del modello, garantendo una previsione precisa e la capacità di considerare intervalli di tempo irregolari tra eventi.
Perché utilizzare la predizione?
L’uso della predizione ci permette di anticipare con alta precisione i risultati futuri di un paziente, analizzando preventivamente i suoi dati attraverso il nostro modello personalizzato TA-LSTM. Per verificare la precisione delle previsioni, abbiamo preso un campione di dati di pazienti reali e abbiamo applicato il modello basandoci sui loro registri di attività precedenti. L’ultimo giorno di attività di ciascun paziente è stato escluso dai dati per confrontare il risultato reale con la previsione generata dal modello.
Nella maggior parte dei casi, i risultati previsti dal nostro modello coincidevano strettamente con i valori reali dei giocatori. Tuttavia, abbiamo anche identificato alcune eccezioni interessanti in cui la previsione differiva in modo significativo dal risultato reale.
Per esempio, nel grafico seguente (Immagine 1), è possibile osservare il progresso del paziente (linea blu) e la corrispondente previsione del modello (linea rossa). A prima vista, la differenza sembra piuttosto grande: il paziente ha mantenuto una performance alta e stabile durante tutto il periodo di osservazione, ma il suo ultimo risultato è stato inaspettatamente molto più basso di quanto previsto. In questo caso, la previsione del modello sembrava molto più logica del risultato reale.
Perché è successo questo?
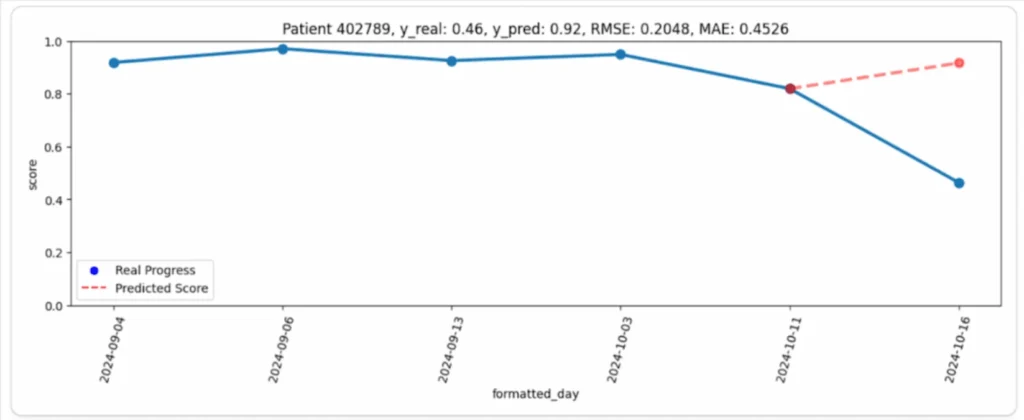
La ragione si è rivelata semplice ma importante: in tutti i giorni precedenti, il paziente ha giocato a livelli (fasi) più facili, ottenendo punteggi costantemente alti. Tuttavia, nell’ultimo giorno ha scelto la fase 6, che era più difficile, provocando un calo notevole nelle sue prestazioni (Immagine 2).
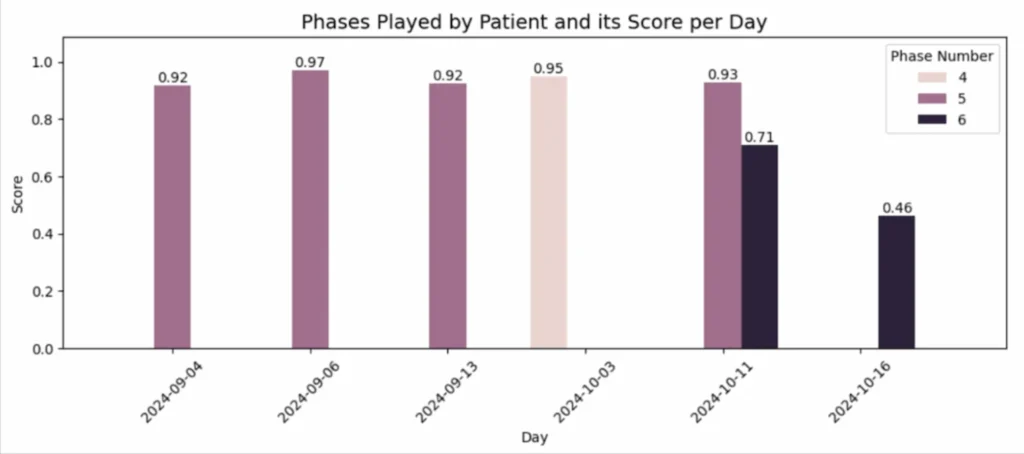
In questo modo, la previsione del modello ha permesso di riconoscere una deviazione inaspettata dal comportamento abituale del paziente, identificando che è stata causata da un aumento del livello di difficoltà.
Questo approccio fornisce ai professionisti di NeuronUP uno strumento potente per rilevare tempestivamente questo tipo di situazioni e analizzare rapidamente le cause delle deviazioni.
Prova NeuronUP gratis per 7 giorni
Potrai collaborare con le nostre attività, progettare sedute o fare riabilitazione a distanza.
Conclusione
L’utilizzo del Time-Aware LSTM apre nuove possibilità per la previsione precisa di serie temporali con intervalli irregolari. A differenza dei modelli tradizionali, TA-LSTM è capace di adattarsi al ritmo unico di ciascun giocatore, tenendo conto delle sue pause e degli intervalli di attività. Grazie a questo approccio, la nostra piattaforma di stimolazione cognitiva non solo può prevedere con precisione i risultati futuri dei pazienti, ma anche rilevare tempestivamente possibili anomalie o deviazioni inaspettate.
In NeuronUP valorizziamo il tuo tempo e cerchiamo sempre di applicare le tecnologie più efficaci, innovative e avanzate. Rimani sintonizzato per i nostri aggiornamenti, il meglio deve ancora arrivare!
Bibliografia
- Lechner, Mathias, and Ramin Hasani. “Learning Long-Term Dependencies in Irregularly-Sampled Time Series.” arXiv preprint arXiv:2006.04418, vol. -, no. -, 2020, pp. 1-11.
- Michigan State University, et al. “Patient Subtyping via Time-Aware LSTM Networks.” Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’17), vol. -, no. -, 2017, pp. 65-74.
- Nguyen, An, et al. “Time Matters: Time-Aware LSTMs for Predictive Business Process Monitoring.” Lecture Notes in Business Information Processing, Process Mining Workshops, vol. 406, no. -, 2021, pp. 112–123.
- Schirmer, Mona, et al. “Modeling Irregular Time Series with Continuous Recurrent Units.” Proceedings of the 39th International Conference on Machine Learning (ICML 2022), vol. 162, no. -, 2022, pp. 19388-19405.
- “Time aware long short-term memory.” Wikipedia, https://en.wikipedia.org/wiki/Time_aware_long_short-term_memory. Accessed 12 March 2025.




Lascia un commento