
Elina Filatova, scientifique des données chez NeuronUP, explique dans cet article comment le modèle Time-Aware LSTM (TA-LSTM) permet de prédire avec une grande précision les résultats des utilisateurs même lorsque leurs données sont générées de manière irrégulière.
Chez NeuronUP, nous mettons en œuvre activement les méthodes d’apprentissage automatique les plus avancées qui nous permettent de prédire avec une grande précision le comportement des utilisateurs, d’identifier les tendances et de prévoir les résultats futurs en nous basant sur leurs données historiques.
Cependant, les approches traditionnelles d’apprentissage automatique rencontrent des difficultés lorsque les données sont générées de façon irrégulière et que les intervalles entre les observations sont chaotiques ou spécifiques à chaque utilisateur. Dans de tels cas, les modèles conventionnels deviennent inefficaces car ils ne tiennent pas compte du rythme et de la fréquence propres à l’activité de chaque personne.
C’est précisément pour résoudre ce problème que nous utilisons une version spéciale du réseau de neurones LSTM, appelée Time-Aware LSTM (TA-LSTM). Ce modèle est capable de prendre efficacement en compte les intervalles temporels entre les événements, permettant de prédire des séries temporelles même lorsque les données sont irrégulières.
Objectif de l’étude et principales difficultés
Chez NeuronUP, nous disposons de métriques des utilisateurs provenant des jours précédents, dans le but de prédire leurs résultats lors de leur prochaine activité. À première vue, cela pourrait sembler une tâche simple, mais dans la pratique, plusieurs difficultés importantes apparaissent :
- Rythme individuel des utilisateurs : Chaque utilisateur a un schéma d’entraînement unique ; certains jouent quotidiennement, d’autres hebdomadairement, et certains peuvent faire des pauses prolongées allant jusqu’à un mois avant de reprendre leurs activités de manière imprévue. Par exemple, Alex s’entraîne de façon régulière chaque jour, tandis que José préfère des intervalles hebdomadaires. Si l’on moyenne leurs résultats sans prendre en compte cette fréquence, on perdra des détails cruciaux.
- Variété des activités et impact différentiel sur les utilisateurs : Les activités de NeuronUP sont conçues pour améliorer différentes fonctions cognitives telles que la mémoire, l’attention et la logique, entre autres. Chaque activité possède un niveau de difficulté particulier qui varie selon l’utilisateur. Ce qui est facile pour une personne peut représenter un grand défi pour une autre.
- Focalisation sur des activités spécifiques : Les spécialistes de NeuronUP déterminent quelles activités attribuer à chaque utilisateur. Par exemple, Carmen effectue régulièrement des exercices de mémoire, de logique et de mathématiques, tandis que Pablo préfère exclusivement des exercices d’attention. Par conséquent, le modèle prédictif doit tenir compte du parcours personnalisé de chaque joueur.
Bien sûr, tous ces détails compliquent à la fois le processus de préparation des données et l’entraînement des modèles d’apprentissage automatique. Ignorer le rythme individuel des joueurs, leurs intervalles irréguliers et les différents niveaux de difficulté des activités conduit inévitablement à la perte d’informations clés. En conséquence, il existe un risque d’obtenir des prédictions moins précises, ce qui peut à son tour réduire l’efficacité des recommandations personnalisées sur NeuronUP.

Abonnez-vous
à notre
Newsletter
Solution : Time-Aware LSTM
Pour surmonter efficacement toutes les difficultés mentionnées ci-dessus, l’équipe data de NeuronUP a développé une solution spécifique basée sur le modèle personnalisé Time-Aware LSTM (TA-LSTM). Il s’agit d’une version améliorée du réseau neuronal LSTM standard, capable de prendre en compte non seulement les événements dans la série temporelle, mais aussi les intervalles de temps entre eux.
Préparation des données : pourquoi la différence temporelle est-elle si importante ?
Notre modèle reçoit en entrée des données préparées de manière spécifique. Chaque enregistrement est une matrice bidimensionnelle contenant les résultats séquentiels d’un joueur, classés chronologiquement, ainsi que les intervalles de temps en jours entre chaque fois qu’il a effectué l’activité. Pour comprendre pourquoi il est si important de considérer la différence temporelle, découvrons deux personnages qui nous aideront à illustrer ce point de manière claire.
Imaginons un marathon nommé « Le plus rapide et agile », pour lequel se préparent deux athlètes :
- Neuronito – un athlète discipliné et déterminé. Il ne manque jamais un entraînement, travaille sur lui-même chaque jour et prend soin de son alimentation avec minutie. Neuronito progresse constamment : à chaque nouvelle séance d’entraînement, il devient plus rapide, plus endurant et plus sûr de lui. Étant donné son rythme de préparation stable, nous pouvons facilement prédire qu’il aura une excellente performance au marathon.

- Lentonito – un athlète talentueux mais moins discipliné. Ses entraînements sont irréguliers. Un jour, il s’entraîne avec enthousiasme, le lendemain il préfère se reposer en profitant d’une paella et d’un bon jambon. Ces séances inconstantes génèrent des fluctuations dans ses performances : parfois il progresse, parfois non, sans croissance stable. Il est probable que Lentonito termine la course avec des résultats moins impressionnants.

De cette façon, nous avons vu à travers un exemple simple à quel point les intervalles de temps entre les événements influent sur les résultats finaux. C’est précisément cette information sur la stabilité et la régularité des « séances d’entraînement » que nous fournissons à notre modèle.
Si nous ne prenons pas en compte les intervalles de temps, le modèle percevrait ces deux athlètes comme identiques, sans noter la différence dans leur approche de l’entraînement. Mais TA-LSTM détecte cette caractéristique clé, analyse les intervalles individuels entre les événements et réalise des prédictions plus précises, tenant compte du rythme unique de chaque participant (ou, dans notre cas sur NeuronUP, de l’utilisateur).
Mais ce n’est pas tout ! Comme vous l’avez peut-être remarqué, nous avons également mentionné l’alimentation de Neuronito et de Lentonito. Ce n’est pas un hasard : ces données représentent des caractéristiques supplémentaires qui influencent elles aussi de manière significative le résultat final.
De même, notre modèle est capable de prendre en compte non seulement les intervalles de temps, mais aussi d’autres caractéristiques importantes, comme l’âge, le sexe, le diagnostic et même les préférences des utilisateurs.
Cela permet d’améliorer considérablement la précision des prédictions, comme dans notre exemple avec les protagonistes, où nous avons pris en compte leur régime alimentaire et son influence sur le succès.
Détails techniques
Maintenant que nous avons vu le concept principal, passons à l’aspect technique du fonctionnement du modèle Time-Aware LSTM (TA-LSTM). Ce modèle est une modification de la cellule LSTM standard, conçue spécifiquement pour prendre en compte les intervalles de temps entre les événements séquentiels.
L’objectif principal de TA-LSTM est la mise à jour adaptative de l’état de mémoire interne du modèle en fonction du temps écoulé depuis la dernière observation. Cette approche est cruciale lorsqu’on travaille avec des séries temporelles irrégulières, exactement le type de données que nous traitons dans NeuronUP.
Le vecteur d’entrée à l’instant t est représenté comme :
[text{inputs}_{t} = [x_{t},,Delta t]]Où :
- (x_t in mathbb{R}^d) – est le vecteur de caractéristiques décrivant l’événement actuel (chaque jour où l’activité est effectuée).
- (Delta t in mathbb{R}) – est l’intervalle de temps entre l’observation actuelle et la précédente.
Les états précédents du modèle sont représentés de manière standard :
[h_{t-1},; C_{t-1}]Où :
- (h_{t-1}) – est le vecteur d’état caché à l’étape précédente. >
- (C_{t-1}) – est l’état de mémoire (cellule LSTM) à l’étape précédente.
Pour prendre en compte l’influence de l’intervalle de temps t, le modèle emploie un mécanisme spécial d’atténuation de la mémoire, décrit par la formule suivante :
[gamma_t = e^{-text{RELU}(w_d cdot Delta t + b_d)}]Où :
- (w_d, ; b_d) – sont des paramètres entraînables du modèle. >
- (mathrm{ReLU}(x) = max(0, x)) – est la fonction d’activation qui évite les valeurs négatives.
Le coefficient d’atténuation (gamma_t) contrôle la mise à jour de l’état de mémoire.
La mise à jour de la mémoire est définie comme :
[bar{C}_{t-1} = gamma_t cdot C_{t-1}]Cela signifie que lorsque l’intervalle de temps augmente, la valeur de (gamma_t) tend vers zéro, ce qui entraîne un plus grand « oubli » des états de mémoire précédents.
À l’étape suivante, l’état de mémoire corrigé (bar{C}_{t-1}) est introduit dans les équations standard de LSTM :
[h_t, ; C_t = text{LSTM}(x_{t’}, h_{t-1}, bar{C}_{t-1})]Les valeurs de sortie (h_t) et l’état de mémoire mis à jour (C_t) sont utilisés à l’étape suivante du modèle, ce qui garantit une prédiction précise et la capacité de prendre en compte des intervalles de temps irréguliers entre les événements.
Pourquoi utiliser la prédiction ?
L’utilisation de la prédiction nous permet d’anticiper avec une haute précision les résultats futurs d’un patient, en analysant préalablement ses données à travers notre modèle personnalisé TA-LSTM. Pour vérifier la précision des prédictions, nous avons pris un échantillon de données de patients réels et appliqué le modèle sur leurs enregistrements d’activité précédents. Le dernier jour d’activité de chaque patient a été exclu des données pour comparer le résultat réel avec la prédiction générée par le modèle.
Dans la plupart des cas, les résultats prédits par notre modèle correspondaient étroitement aux valeurs réelles des joueurs. Cependant, nous avons également identifié quelques exceptions intéressantes où la prédiction différait significativement du résultat réel.
Par exemple, dans le graphique suivant (Image 1), on peut observer l’évolution du patient (ligne bleue) et la prédiction correspondante du modèle (ligne rouge). À première vue, la différence semble assez importante : le patient a maintenu une performance élevée et stable pendant toute la période d’observation, mais son dernier résultat a été étonnamment beaucoup plus faible que prévu. Dans ce cas, la prédiction du modèle semblait beaucoup plus logique que le résultat réel.
Pourquoi cela s’est-il produit ?
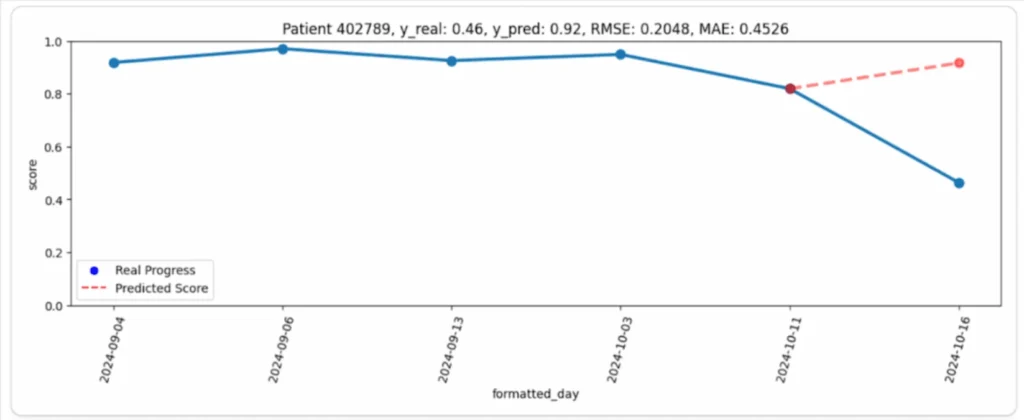
La raison s’est avérée simple mais importante : pendant tous les jours précédents, le patient a joué à des niveaux (phases) plus faciles, obtenant des scores constamment élevés. Cependant, le dernier jour, il a choisi la phase 6, qui était plus difficile, ce qui a provoqué une chute notable de sa performance (Image 2).
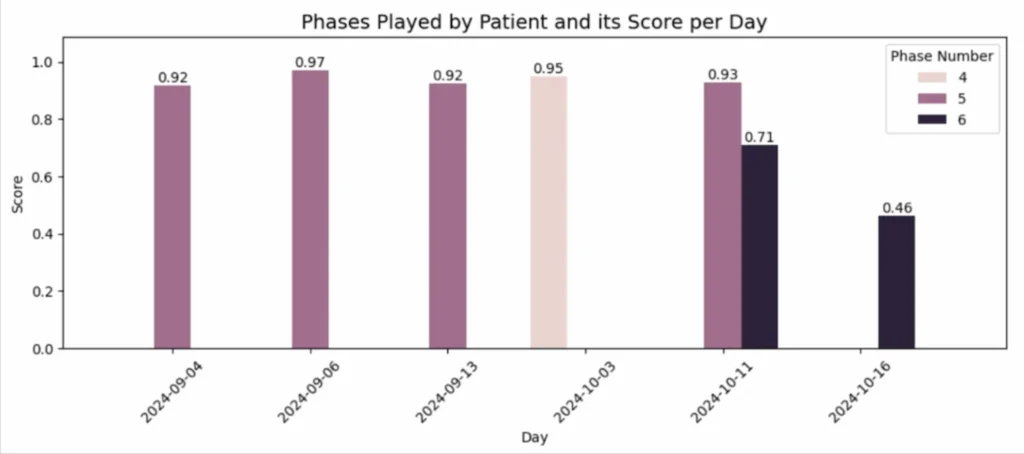
De cette manière, la prédiction du modèle a permis de reconnaître un écart inattendu par rapport au comportement habituel du patient, en identifiant qu’il était causé par une augmentation du niveau de difficulté.
Cette approche fournit aux professionnels de NeuronUP un outil puissant pour détecter à temps ce type de situations et analyser rapidement les causes des déviations.
Essayez NeuronUP 7 jours gratuitement
Vous pourrez travailler avec nos activités, concevoir des séances ou effectuer des réhabilitations à distance
Conclusion
L’utilisation de Time-Aware LSTM ouvre de nouvelles possibilités pour la prédiction précise de séries temporelles à intervalles irréguliers. Contrairement aux modèles traditionnels, TA-LSTM est capable de s’adapter au rythme unique de chaque joueur, en tenant compte de leurs pauses et de leurs intervalles d’activité. Grâce à cette approche, notre plateforme de stimulation cognitive peut non seulement prédire avec précision les résultats futurs des patients, mais également détecter de manière opportune d’éventuelles anomalies ou déviations inattendues.
Chez NeuronUP, nous apprécions votre temps et nous nous efforçons toujours d’appliquer les technologies les plus efficaces, innovantes et avancées. Restez à l’écoute de nos mises à jour, le meilleur est à venir !
Bibliographie
- Lechner, Mathias, and Ramin Hasani. “Learning Long-Term Dependencies in Irregularly-Sampled Time Series.” arXiv preprint arXiv:2006.04418, vol. -, no. -, 2020, pp. 1-11.
- Michigan State University, et al. “Patient Subtyping via Time-Aware LSTM Networks.” Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’17), vol. -, no. -, 2017, pp. 65-74.
- Nguyen, An, et al. “Time Matters: Time-Aware LSTMs for Predictive Business Process Monitoring.” Lecture Notes in Business Information Processing, Process Mining Workshops, vol. 406, no. -, 2021, pp. 112–123.
- Schirmer, Mona, et al. “Modeling Irregular Time Series with Continuous Recurrent Units.” Proceedings of the 39th International Conference on Machine Learning (ICML 2022), vol. 162, no. -, 2022, pp. 19388-19405.
- “Time aware long short-term memory.” Wikipedia, https://en.wikipedia.org/wiki/Time_aware_long_short-term_memory. Consulté le 12 mars 2025.







Laisser un commentaire