
في هذا المقال، تعرض طالبة الدكتوراه Marta Arbizu Gómez الدراسة «النماذج اللغوية الكبيرة تفكك الحدس السريري في تشخيص التوحد»، التي تستكشف تأثير استخدام نماذج لغوية واسعة النطاق في تشخيص التوحد.
مقدمة
كان تشخيص اضطراب طيف التوحد (ASD) تقليديًا مهمة معقدة تعتمد بدرجة كبيرة على الخبرة السريرية، والملاحظة الدقيقة، وتفسير سلوكيات متنوعة. على الرغم من وجود إرشادات تشخيصية محددة جيدًا مثل DSM-5، فإن الممارسة السريرية غالبًا ما تُوجَّه بـ«حدس» يطوره المحترفون بعد سنوات من الخبرة. لكن ماذا لو كان بإمكاننا «قراءة» ذلك الحدس وفهمه بمنهج أكثر موضوعية؟
دراسة حديثة نُشرت في مجلة Cell وعنوانها “Large language models deconstruct the clinical intuition behind diagnosing autism”، تستكشف بالضبط هذه الإمكانية: استخدام نماذج لغوية واسعة النطاق (LLMs، اختصارًا بالإنجليزية) للكشف عن الأنماط التي يتبعها الأطباء عند تشخيص التوحد. النتائج ليست مفاجئة فحسب، بل قد يكون لها تداعيات عميقة على كيفية فهمنا وإجرائنا لتشخيصات ASD في الوقت الحاضر.
السياق: لماذا من الضروري مراجعة طريقة تشخيصنا للتوحد؟
اضطراب طيف التوحد (ASD) هو اضطراب من اضطرابات النمو العصبي يتميز بـصعوبات في التواصل الاجتماعي وأنماط سلوكية واهتمامات مقيدة ومتكررة. ومع ذلك، يمكن أن تظهر هذه السمات بتنوع كبير بين الأفراد، مما يجعل التشخيص عملية دقيقة وفي بعض الأحيان ذاتية.
بالإضافة إلى ذلك، على الرغم من أن الأدوات التشخيصية المعيارية مثل ADOS أو ADI‑R توفر هيكلة للعملية، فإن العديد من التشخيصات تعتمد على تقارير سردية كتبها الأطباء الذين راقبوا المريض. بمعنى آخر، طريقة وصف الطبيب للمريض قد يكون لها وزن كبير في التشخيص النهائي.
أمام هذه الحقيقة، طرح الباحثون سؤالًا أساسيًا: ما العناصر داخل هذه التقارير المكتوبة التي توجه بالفعل قرارات التشخيص؟
ماذا فعل الباحثون؟
جمع مؤلفو الدراسة أكثر من 40.000 تقريرًا سريريًا للأطفال من نظام الصحة العامة في ماساتشوستس. كانت هذه التقارير، التي كتبها متخصصو الصحة العقلية، تحتوي على أوصاف مفصلة لسلوكيات المرضى ووظيفتهم.
استنادًا إلى هذه القاعدة البيانية، قام الباحثون بتدريب عدة نماذج لغوية، من ضمنها GPT-4 (الذي طوّرته OpenAI) ونموذج سريري مفتوح المصدر يُدعى Clinician-LLaMA. الفكرة كانت أن تتعلم النماذج التنبؤ بما إذا كان التقرير السريري يُشير إلى مريض شخص مُشخّص بالتوحد أم لا، اعتمادًا فقط على النص.
كانت النتائج مفاجئة: تمكنت النماذج من تحقيق دقة ملحوظة في التصنيف، حتى عندما تم إخفاء معلومات أساسية مثل جنس أو عمر المريض. وهذا يوحي بأن التقارير تحتوي على أنماط لغوية ضمنية تستطيع النماذج اكتشافها والتي تعكس كيف يتخذ الأطباء قراراتهم.
ماذا وجدوا؟
بعيدًا عن الدقة في التنبؤ، كان الأكثر إثارة ما كشفته النماذج عن عملية التشخيص نفسها. عند تحليل الأجزاء النصية ذات الوزن الأكبر في قرارات النموذج، حدد الباحثون أن أنواعًا معينة من السلوكيات والأوصاف كانت أكثر حسمًا من غيرها.
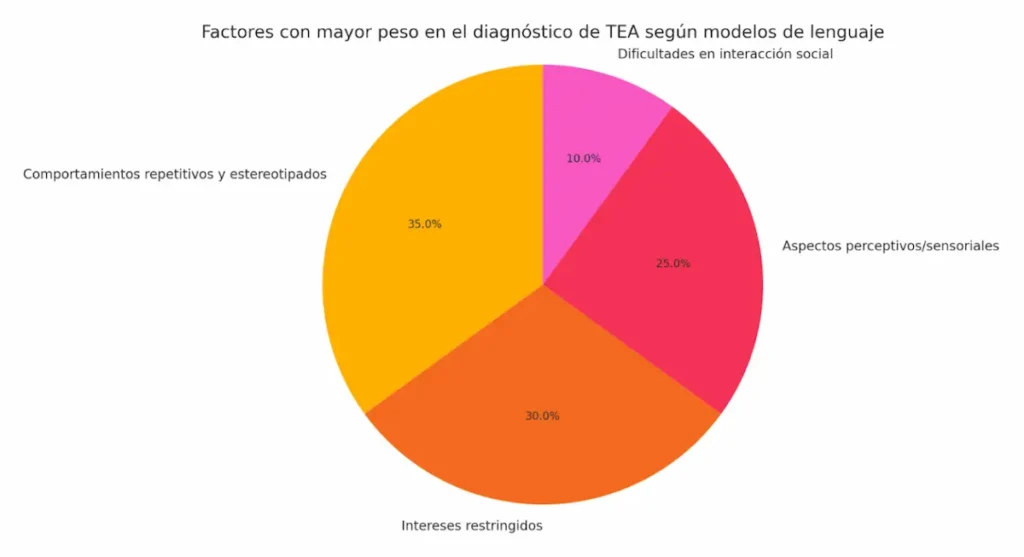
كما نرى في المخطط، كانت السلوكيات التكرارية والنمطية، والاهتمامات المقيدة، والجوانب المتعلقة بالإدراك الحسي هي العوامل الأكثر ارتباطًا بتشخيص إيجابي لاضطراب طيف التوحد. وعلى العكس من ذلك، بدت الصعوبات في التفاعل الاجتماعي، التي تُعد أحد أعمدة التشخيص التقليدية وفق DSM-5، أقل وزناً في النماذج.
هذا لا يعني أن الصعوبات الاجتماعية غير ذات صلة، بل إنه في الممارسة يبدو أن الأطباء يُعطون اهتمامًا أكبر —ربما بشكل غير واعٍ— لأنماط سلوكية أخرى عند اتخاذ قرار ما إذا كان المريض يستوفي معايير التشخيص.
فيما يلي ملخص لأهم نتائج الدراسة في جدول لتسهيل الفهم:
| البند الذي حلل | النتيجة / الملاحظة |
|---|---|
| النموذج المستخدم | GPT-4 و Clinician-LLaMA (نماذج لغوية مدرّبة على تقارير سريرية). |
| مصدر البيانات | أكثر من 40.000 تقريرًا سريريًا للأطفال من نظام الصحة العامة في Massachusetts. |
| مهمة النموذج | التنبؤ بما إذا كان المريض قد شُخّص بالتوحد اعتمادًا فقط على نص التقرير. |
| دقة النموذج | عالية، حتى عند إخفاء متغيرات مثل الجنس أو العمر. |
| العوامل الأكثر حسمًا في التشخيص | السلوكيات التكرارية، الاهتمامات المقيدة والسمات الحسية/الإدراكية. |
| العوامل الأقل حسمًا | صعوبات في التفاعل الاجتماعي. |
| الأثر الرئيسي | في الممارسة السريرية، تؤثر السلوكيات القابلة للملاحظة أكثر مما كان متوقعًا. |
| التأثير المحتمل على معايير التشخيص | يشير إلى ضرورة إعادة تقييم وزن بعض المعايير في DSM-5. |
| تطبيق الذكاء الاصطناعي في الصحة النفسية | كأداة لدعم التشخيص وتحليل المنطق السريري. |
كما يمكن ملاحظته، لم تقتصر قدرة نماذج اللغة على التنبؤ بتشخيص ASD بدقة عالية فحسب، بل كشفت أيضًا أن أنماطًا سلوكية معينة —وخاصة السلوكيات التكرارية والاهتمامات المقيدة— لها تأثير أكبر في الممارسة السريرية مما توحي به المعايير التشخيصية التقليدية. وهذا يفتح الباب أمام إعادة التفكير في كيفية تطبيق هذه المعايير في سياق الحياة الواقعية.
التداعيات: هل يجب إعادة التفكير في معايير تشخيص التوحد؟
تفتح هذه النتائج نقاشًا مهمًا: هل تعكس المعايير التشخيصية الحالية بالفعل الطريقة التي يقيم بها المحترفون المرضى؟
إذا كان الأطباء، بشكل منهجي، يعطون أهمية أكبر للسلوكيات القابلة للملاحظة مثل الحركات النمطية أو الاهتمامات المقيدة، فقد يكون من الضروري إعادة تقييم الوزن الممنوح لكل فئة تشخيصية في الإرشادات الرسمية.
علاوة على ذلك، قد يكون لهذا المنهج تداعيات على تدريب المهنيين الجدد، الذين قد يستفيدون من فهم كيفية تطبيق المعايير في الممارسة الفعلية، بعيدًا عن الجانب النظري فقط.
هل يمكن للذكاء الاصطناعي أن يساعد في التشخيص السريري لاضطراب طيف التوحد؟
من أهم وعود الذكاء الاصطناعي في مجال الصحة قدرته على اكتشاف أنماط معقدة في أحجام كبيرة من البيانات. في هذه الحالة، لا تعمل نماذج اللغة كأدوات تصنيف فحسب، بل أيضًا كـوسائل تجعل ما هو غير مرئي مرئيًا: المنطق الضمني وراء القرارات السريرية.
بعيدًا عن استبدال المحترفين، يمكن لهذه النماذج أن تكون حلفاء، تقدم رأيًا ثانيًا مستندًا إلى آلاف الحالات السابقة، وتساعد في كشف التحيزات أو التناقضات في عمليات التشخيص.
أين يمكن أن تساهم NeuronUP في دراسات مثل هذه؟
يمكن أن تساهم NeuronUP بشكل كبير في دراسات من هذا النوع من خلال تسهيل التكرار في مجموعات سكانية أكثر تنوعًا وغير متحدثة بالإنجليزية، بفضل تواجدها الدولي. منصتها، التي تضم مئات الأنشطة المعرفية، ستسمح بتكملة تحليل التقارير السريرية ببيانات منظمة حول الأداء المعرفي. علاوة على ذلك، يمكن تطبيق هذا النهج على حالات سريرية أخرى مثل اضطراب نقص الانتباه مع فرط النشاط أو الخلل المعرفي الطفيف، مما يحسّن الكشف المبكر ودقة التشخيص.
خلاصة الدراسة
تشكل هذه الدراسة علامة فارقة عند تقاطع الذكاء الاصطناعي والصحة النفسية. من خلال استخدام نماذج لغوية لتحليل التقارير السريرية، لم يُظهر الباحثون أن تشخيص التوحد يمكن التنبؤ به بدقة ملحوظة فحسب، بل كشفوا أيضًا كيف يُبنى «الحدس السريري» الذي يوجّه هذه القرارات.
في المستقبل القريب، قد تُدمَج أدوات مثل هذه في أنظمة الصحة لتقديم دعم تشخيصي، تحسين تدريب المهنيين، وربما حتى إعادة تعريف المعايير التي نفهم بها التوحد. وما يتضح هو أن الذكاء الاصطناعي لا يغير التكنولوجيا فحسب، بل أيضًا طريقتنا في فهم العقل البشري.
المراجع
- Feng S, Sondhi R, Tu X, Buckley J, Sands A, Comiter A, Zhang H, Gao R, Sragovich S, Mello JD, Fedorenko E, Saxe R, Sontheimer EJ, Sapiro G, O’Reilly UM, McCoy TH, Beam AL. Large language models deconstruct the clinical intuition behind diagnosing autism. Cell. 2024 Mar 21. doi: 10.1016/j.cell.2024.03.004.
إذا أعجبتك هذه التدوينة عن كيف يمكن لنماذج اللغة مثل ChatGPT أن تساعد في تشخيص التوحد، فمن المؤكد أن هذه المقالات من NeuronUP ستهمك:




“تمت ترجمة هذا المقال. رابط المقال الأصلي باللغة الإسبانية:”
¿Pueden los modelos de lenguaje tipo ChatGPT ayudar a diagnosticar el autismo?
 إعادة التأهيل العصبي وتحفيز الوظائف التنفيذية في بيئة العمل
إعادة التأهيل العصبي وتحفيز الوظائف التنفيذية في بيئة العمل


اترك تعليقاً