
إلينا فيلاتوفا، عالمة بيانات في NeuronUP، تشرح في هذا المقال كيف يُمكّن نموذج LSTM المراعية للزمن (Time-Aware LSTM، TA-LSTM) من التنبؤ بدقةٍ عالية بنتائج المستخدمين حتى عندما تُنشأ بياناتهم بشكلٍ غير منتظم.
في NeuronUP نقوم بتطبيق أكثر أساليب التعلم الآلي تقدماً بنشاط، والتي تُمكّننا من التنبؤ بدقةٍ عالية بسلوك المستخدمين، وتحديد الاتجاهات، وتوقع النتائج المستقبلية استناداً إلى بياناتهم التاريخية.
ومع ذلك، تواجه الطرق التقليدية في التعلم الآلي صعوبات عندما تُنشأ البيانات بشكل غير منتظم وتكون الفواصل الزمنية بين الملاحظات فوضوية أو خاصة بكل مستخدم. في مثل هذه الحالات، تصبح النماذج التقليدية غير فعّالة لأنها لا تراعي إيقاع وتواتر نشاط كل شخصٍ فريد.
وبالتحديد لحل هذه المشكلة نستخدم نسخة خاصة من الشبكة العصبية LSTM تُدعى Time-Aware LSTM (TA-LSTM). هذا النموذج قادر على مراعاة الفواصل الزمنية بين الأحداث بفعالية، مما يسمح بالتنبؤ بالسلاسل الزمنية حتى عندما تكون البيانات غير منتظمة.
هدف الدراسة والصعوبات الرئيسية
في NeuronUP نمتلك مقاييس المستخدم المستمدة من الأيام السابقة، بهدف التنبؤ بنتائجهم في المرة التالية التي يؤدون فيها النشاط. للوهلة الأولى، قد يبدو هذا مهمة بسيطة، لكن في الممارسة العملية تظهر عدة صعوبات مهمة:
- الإيقاع الفردي للمستخدمين: لكل مستخدم نمط تدريب فريد؛ بعضهم يلعب يومياً، وآخرون أسبوعياً، وبعضهم قد يأخذون فترات توقف طويلة تصل إلى شهر، ويعودون بشكلٍ غير متوقع إلى الأنشطة. على سبيل المثال، أليكس يتدرب بانتظام كل يوم، بينما خوسيه يفضل الفواصل الأسبوعية. إذا تم أخذ متوسط نتائجهم دون مراعاة هذا التواتر، فستنضيع تفاصيل حاسمة.
- تنوع الأنشطة وتأثيرها المختلف على المستخدمين: تم تصميم الأنشطة في NeuronUP لتحسين وظائف معرفية مختلفة مثل الذاكرة والانتباه والمنطق، وغيرها. كل نشاط له مستوى صعوبة خاص يتباين باختلاف المستخدم. ما قد يكون سهلاً لشخصٍ ما، قد يمثل تحدياً كبيراً لآخر.
- التركيز على أنشطة محددة: يحدد اختصاصيو NeuronUP الأنشطة التي تُسند إلى كل مستخدم. على سبيل المثال، كارمن تقوم بانتظام بتمارين الذاكرة والمنطق والرياضيات، بينما بابلو يفضّل تمارين الانتباه حصراً. لذلك، يجب على النموذج التنبؤي أن يأخذ في الاعتبار المسار الشخصي لكل لاعب.
بالطبع، كل هذه التفاصيل تُعقّد كلاً من عملية التحضير الصحيحة للبيانات وذات عملية تدريب نماذج التعلم الآلي. تجاهل الإيقاع الفردي للاعبين، وفواصلهم الزمنية غير المنتظمة، ومستويات الصعوبة المختلفة للأنشطة يؤدي حتماً إلى فقدان معلوماتٍ رئيسية. ونتيجةً لذلك، يزداد احتمال الحصول على تنبؤات أقل دقة، مما قد يقلل من فعالية التوصيات المخصّصة في NeuronUP.
الحل: Time-Aware LSTM
لتجاوز بفعالية كل الصعوبات المذكورة أعلاه، طوّر فريق البيانات في NeuronUP حلّاً مُخصّصاً يستند إلى نموذج Time-Aware LSTM (TA-LSTM) المخصّص. هذه نسخة محسّنة من خلية LSTM القياسية، قادرة على مراعاة ليس فقط الأحداث في السلاسل الزمنية، بل أيضاً الفواصل الزمنية بينها.
تحضير البيانات: لماذا الاختلاف الزمني مهم جداً؟
يتلقى نموذجنا مُدخلاتٍ مُعدة بطريقةٍ محددة. كل سجل هو مصفوفة ثنائية الأبعاد تحتوي على نتائج اللاعب المتسلسلة، مرتبة زمنياً، وكذلك الفواصل الزمنية بالأيام بين كل مرة أجرى فيها النشاط. لفهم لماذا من المهم اعتبار الفرق الزمني، دعونا نتعرّف على شخصيتين سيساعداننا على توضيح هذه النقطة بوضوح.
تخيّل ماراثوناً يُدعى “الأسرع والأكثر رشاقة”، يستعد له رياضيان:
- Neuronito – رياضي منضبط ومصمّم. لا يفوت أبداً تدريباً، يعمل على نفسه كل يوم ويهتم بنظامه الغذائي بدقة. يتقدم Neuronito باستمرار: مع كل جلسة تدريب جديدة يصبح أسرع وأكثر تحملًا وواثقًا بنفسه. بالنظر إلى استقراره في الإعداد، يمكننا بسهولة التنبؤ بأداء ممتاز في الماراثون.

- Lentonito – رياضي موهوب لكنه أقل انضباطاً. تدريباته غير منتظمة. اليوم يتدرب بحماس، وغداً يفضّل الراحة والاستمتاع ببايلا وقطع لحم خنزير جيدة. هذه الجلسات المتقلبة تُولّد تذبذبات في أدائه: أحياناً يتحسّن، وأحياناً لا، لكن دون نمو ثابت. من المرجح أن يصل Lentonito إلى خط النهاية بنتائج أقل إثارة للإعجاب.

بهذه الطريقة، رأينا بمثالٍ بسيط مدى تأثير الفواصل الزمنية بين الأحداث على النتائج النهائية. وهذه بالضبط هي المعلومات المتعلقة بالاستقرار والانتظام في “التدريبات” التي نزوّد بها نموذجنا.
إذا لم نأخذ الفواصل الزمنية في الاعتبار، فسيُصنّف النموذج هذين الرياضيين على أنهما متشابهان، دون أن يلاحظ الفرق في نهجهما التدريب. لكن TA-LSTM يلتقط هذه الخاصية الأساسية، يحلل الفواصل الفردية بين الأحداث ويُجري تنبؤات أكثر دقة، مع مراعاة الإيقاع الفريد لكل مشارك (أو في حالتنا في NeuronUP، لكل مستخدم).
ولكن هذا ليس كل شيء! كما قد لاحظت، ذكرنا أيضاً النظام الغذائي لـ Neuronito وLentonito. ليس عبثاً بالطبع، بل لأن هذه البيانات تمثّل ميزات إضافية تؤثر بشكل كبير أيضاً على النتيجة النهائية.
وبالمثل، قادر نموذجنا على مراعاة ليس فقط الفواصل الزمنية، بل أيضاً ميزات مهمة أخرى، مثل العمر، والجنس، والتشخيص، وحتى تفضيلات المستخدمين.
هذا يُحسّن بشكل كبير من دقة التنبؤات، كما في مثالنا مع البطلين، حيث أخذنا بعين الاعتبار نظامهم الغذائي وتأثيره على النجاح.
تفاصيل تقنية
الآن بعد أن استعرضنا المفهوم الرئيسي، لننتقل إلى الجانب التقني لعمل نموذج Time-Aware LSTM (TA-LSTM). هذا النموذج تعديل على خلية LSTM القياسية، صُمم خصيصاً لأخذ الفواصل الزمنية بين الأحداث المتسلسلة في الاعتبار.
الهدف الرئيسي لـ TA-LSTM هو التحديث التكيفي للحالة الداخلية لذاكرة النموذج اعتماداً على الزمن المنقضي منذ الملاحظة الأخيرة. هذا النهج حاسم عند العمل مع سلاسل زمنية غير منتظمة، وهو بالضبط نوع البيانات التي نتعامل معها في NeuronUP.
متجه الإدخال في الزمن t معرّف كالتالي:
\[\text{inputs}_{t} = [x_{t},\,\Delta t]\]حيث:
- \(x_t \in \mathbb{R}^d\) – هو متجه المميزات الذي يصف الحدث الحالي (كل يوم يُؤدى فيه النشاط).
- \(\Delta t \in \mathbb{R}\) – هو الفاصل الزمني بين الملاحظة الحالية والسابقة.
تمثل الحالات السابقة للنموذج بالطريقة القياسية:
\[h_{t-1},\; C_{t-1}\]حيث:
- \(h_{t-1}\) – هو متجه الحالة المخفية في الخطوة السابقة.
- \(C_{t-1}\) – هي حالة الذاكرة (خلية LSTM) في الخطوة السابقة.
لأخذ تأثير الفاصل الزمني t في الحسبان، يستخدم النموذج آلية خاصة لخفض الذاكرة، موصوفة بالمعادلة التالية:
\[\gamma_t = e^{-\text{RELU}(w_d \cdot \Delta t + b_d)}\]حيث:
- \(w_d, \; b_d\) – هي معاملات قابلة للتدريب ضمن النموذج.
- \(\text{RELU}(x) = \max(0, x)\) – هي دالة التفعيل التي تمنع القيم السالبة.
معامل التخميد \(\gamma_t\) يتحكم في تحديث حالة الذاكرة.
يُعرّف تحديث الذاكرة كالتالي:
\[\bar{C}_{t-1} = \gamma_t \cdot C_{t-1}\]هذا يعني أنه عندما يزداد الفاصل الزمني، تميل قيمة إلى الصفر، مما يؤدي إلى “نسيان” أكبر لحالات الذاكرة السابقة.
في الخطوة التالية، يتم إدخال حالة الذاكرة المصححة \(\bar{C}_{t-1}\) في معادلات LSTM القياسية:
\[h_t, \; C_t = \text{LSTM}(x_{t’}, h_{t-1}, \bar{C}_{t-1})\]تُستخدم قيم الإخراج \(h_t\) وحالة الذاكرة المحدثة \(C_t\) في الخطوة التالية للنموذج، مما يضمن تنبؤاً دقيقاً والقدرة على مراعاة الفواصل الزمنية غير المنتظمة بين الأحداث.
لماذا استخدام التنبؤ؟
يُتيح لنا استخدام التنبؤ التوقع بدقةٍ عالية لنتائج المريض المستقبلية، من خلال تحليل بياناته مسبقاً عبر نموذجنا المخصّص TA-LSTM. للتحقق من دقة التنبؤات، أخذنا عينة من بيانات مرضى حقيقيين وطبّقنا النموذج اعتماداً على سجلات نشاطهم السابقة. تم استبعاد آخر يوم نشاط لكل مريض من البيانات لمقارنة النتيجة الحقيقية مع التنبؤ الذي أنتجه النموذج.
في معظم الحالات، تطابقت النتائج المتوقعة من قبل نموذجنا بشكل وثيق مع القيم الحقيقية للاعبين. ومع ذلك، حددنا أيضاً بعض الاستثناءات المثيرة للاهتمام حيث اختلف التنبؤ اختلافاً كبيراً عن النتيجة الحقيقية.
على سبيل المثال، في الرسم البياني التالي (الصورة 1)، يمكن ملاحظة تقدم المريض (الخط الأزرق) والتنبؤ المقابل للنموذج (الخط الأحمر). من الوهلة الأولى، تبدو الفجوة كبيرة إلى حدٍ ما: حافظ المريض على أداء عالٍ ومستقر طوال فترة الملاحظة، لكن نتيجته الأخيرة كانت أقل بكثير من المتوقع بشكلٍ غير متوقع. في هذه الحالة، بدا تنبؤ النموذج أكثر منطقية بكثير من النتيجة الحقيقية.
لماذا حدث ذلك؟
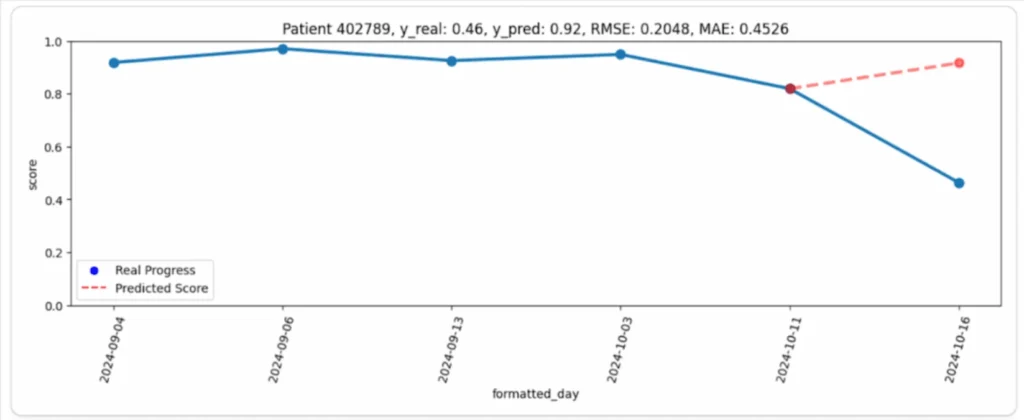
اتضح أن السبب بسيط لكنه مهم: في جميع الأيام السابقة، لعب المريض بمستويات (مراحل) أسهل، فحقق درجاتٍ مرتفعة باستمرار. ومع ذلك، في اليوم الأخير، اختار المرحلة 6 التي كانت أصعب، مما تسبب في تراجع ملحوظ في أدائه (الصورة 2).
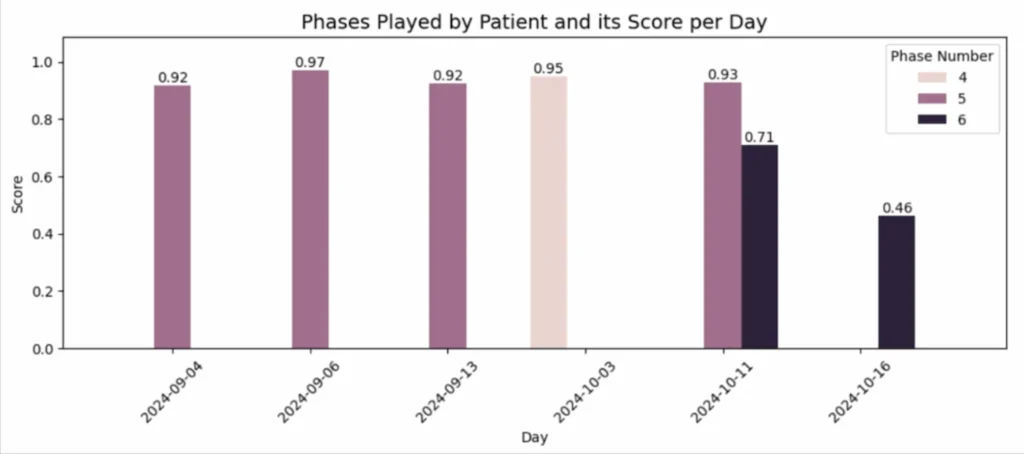
بهذه الطريقة، سمح تنبؤ النموذج بالتعرّف على انحراف غير متوقع عن السلوك المعتاد للمريض، مع تحديد أنه نَجم عن زيادة في مستوى الصعوبة.
يوفّر هذا النهج لأخصائيي NeuronUP أداة قوية للكشف مبكراً عن مثل هذه الحالات وتحليل أسباب الانحراف بسرعة.
الخلاصة
يفتح استخدام Time-Aware LSTM آفاقاً جديدة للتنبؤ الدقيق بالسلاسل الزمنية ذات الفواصل غير المنتظمة. على عكس النماذج التقليدية، فإن TA-LSTM قادر على التكيّف مع الإيقاع الفريد لكل لاعب، مع مراعاة فترات التوقف والفواصل في النشاط. بفضل هذا النهج، لا تقتصر قدرة منصتنا للتحفيز المعرفي على التنبؤ بدقة بنتائج المرضى المستقبلية فحسب، بل تمتد أيضاً إلى الكشف في الوقت المناسب عن الشذوذات أو الانحرافات غير المتوقعة.
في NeuronUP نُقدّر وقتك ونسعى دائماً لتطبيق أكثر التقنيات فاعليةً وابتكاراً وتقدماً. تابع تحديثاتنا، الأفضل قادم!
المراجع
- Lechner, Mathias, and Ramin Hasani. “Learning Long-Term Dependencies in Irregularly-Sampled Time Series.” arXiv preprint arXiv:2006.04418، المجلد -، العدد -، 2020، ص. 1-11.
- Michigan State University, et al. “Patient Subtyping via Time-Aware LSTM Networks.” Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’17)، المجلد -، العدد -، 2017، ص. 65-74.
- Nguyen, An, et al. “Time Matters: Time-Aware LSTMs for Predictive Business Process Monitoring.” Lecture Notes in Business Information Processing, Process Mining Workshops، المجلد 406، العدد -، 2021، ص. 112–123.
- Schirmer, Mona, et al. “Modeling Irregular Time Series with Continuous Recurrent Units.” Proceedings of the 39th International Conference on Machine Learning (ICML 2022)، المجلد 162، العدد -، 2022، ص. 19388-19405.
- “Time aware long short-term memory.” Wikipedia, https://en.wikipedia.org/wiki/Time_aware_long_short-term_memory. تم الوصول إليه في 12 مارس 2025.
إذا أعجبك هذا المقال حول التنبؤ بنتائج اللاعبين بواسطة TA-LSTM، فمن المؤكد أن هذه المقالات من NeuronUP ستهمك:





“تمت ترجمة هذا المقال. رابط المقال الأصلي باللغة الإسبانية:”
Predicción de resultados de jugadores mediante TA-LSTM.
 الرقمنة في التقييم العصبي النفسي
الرقمنة في التقييم العصبي النفسي


اترك تعليقاً