

Le Q-learning (apprentissage Q en français) a considérablement évolué depuis les premières expériences comportementales telles que le conditionnement classique de Pavlov, pour devenir l’une des techniques les plus importantes dans le domaine du Machine Learning (apprentissage automatique). Nous explorerons ci-après son développement et son application dans la neuroréhabilitation et la stimulation cognitive.
Les expériences de Pavlov
Ivan Pavlov, un physiologiste russe de la fin du XIXe siècle, est reconnu pour avoir posé les bases de la psychologie comportementale à travers ses expériences sur le conditionnement classique. Dans ces expériences, Pavlov a démontré que les chiens pouvaient apprendre à associer un stimulus neutre, tel que le son d’une cloche, à un stimulus inconditionné, comme la nourriture, provoquant ainsi une réponse inconditionnée : la salivation.

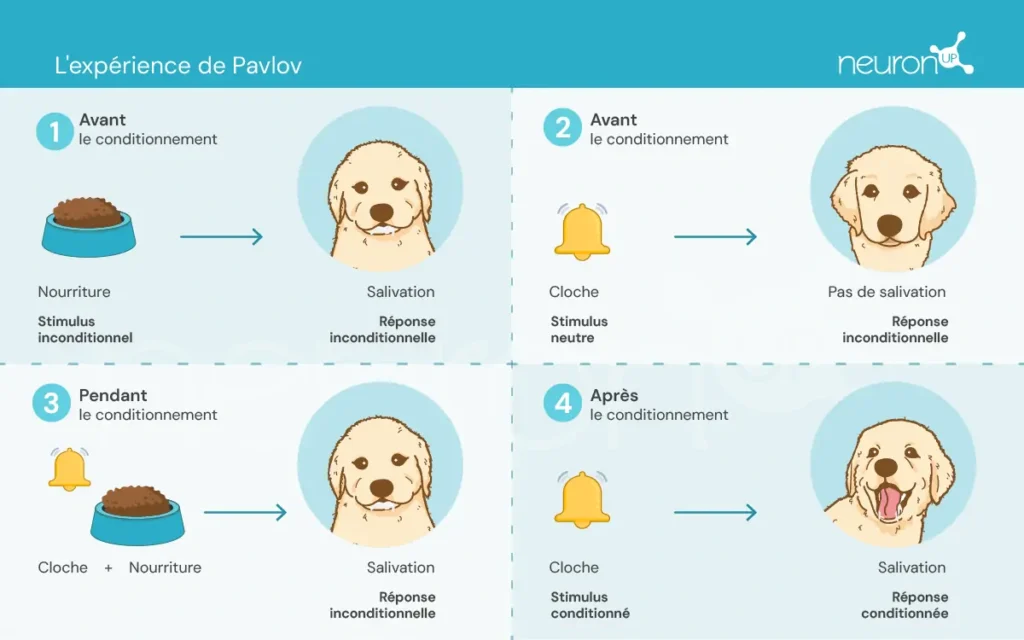
Cette expérience a été fondamentale pour démontrer que le comportement peut être acquis par association, un concept crucial qui a ensuite influencé le développement des théories de l’apprentissage par renforcement.
Les théories de l’apprentissage par renforcement
Ces théories se concentrent sur la manière dont les êtres humains et les animaux apprennent des comportements à partir des conséquences de leurs actions, ce qui a été essentiel pour la conception d’algorithmes tels que le Q-learning.
Il y a quelques concepts clés avec lesquels nous devons nous familiariser avant de continuer :
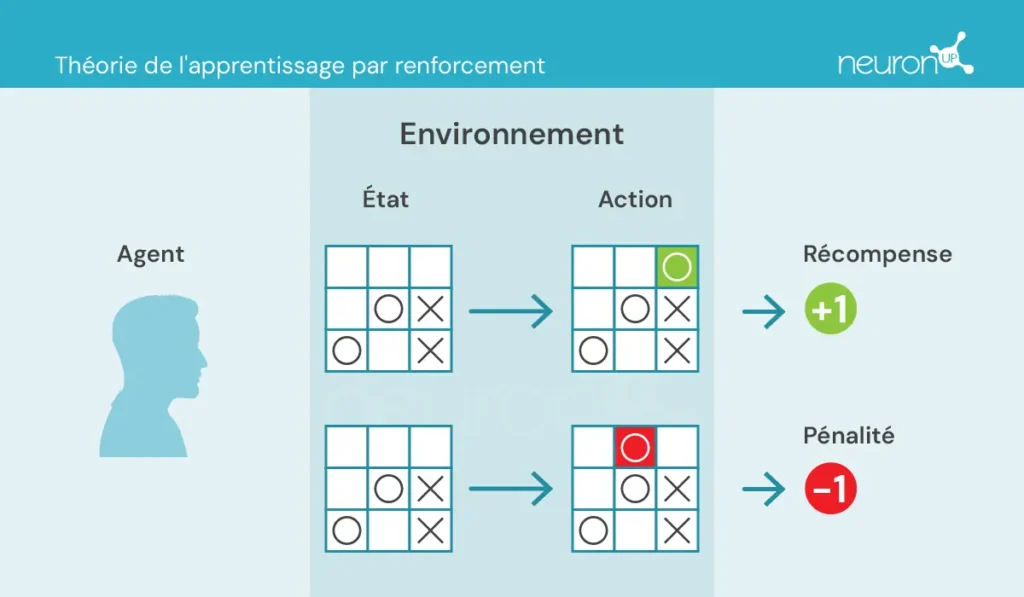
- Agent : chargé de réaliser l’action.
- Environnement : cadre dans lequel l’agent se déplace et interagit.
- État : situation actuelle de l’environnement.
- Action : décisions possibles prises par l’agent.
- Récompense : gratifications attribuées à l’agent.
Dans ce type d’apprentissage, un agent entreprend ou réalise des actions dans l’environnement, reçoit des informations sous forme de récompense/pénalité et les utilise pour ajuster son comportement au fil du temps.

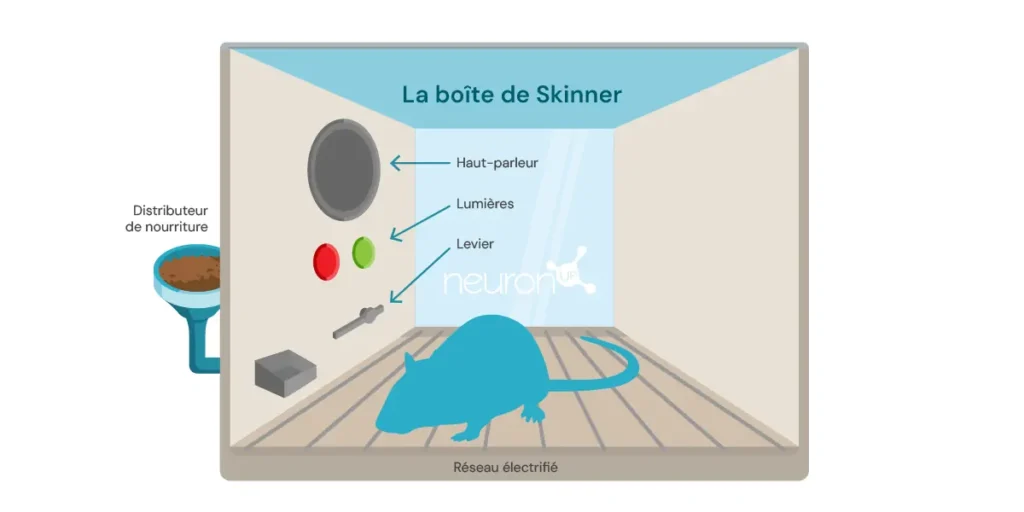
Une expérience classique de l’apprentissage par renforcement est l’expérience de la boîte de Skinner, réalisée par le psychologue américain Burrhus Frederic Skinner en 1938. Dans cette expérience, Skinner a démontré que les rats pouvaient apprendre à appuyer sur un levier pour obtenir de la nourriture, en utilisant le renforcement positif comme moyen de modeler le comportement.
L’expérience consiste à introduire un rat dans une boîte contenant un levier qu’il peut actionner, un distributeur de nourriture, et parfois une lumière et un haut-parleur.
Chaque fois que le rat appuie sur le levier, un grain de nourriture est libéré dans le distributeur. La nourriture agit comme un renforcement positif, une récompense pour avoir appuyé sur le levier. Avec le temps, le rat commence à appuyer plus fréquemment sur le levier, démontrant ainsi qu’il a appris ce comportement grâce au renforcement.

Ce type d’apprentissage a servi de base pour des algorithmes de machine learning, tels que le Q-learning, qui permet aux machines d’apprendre des comportements optimaux de manière autonome grâce à la méthode de l’essai-erreur.
Qu’est-ce que le Q-learning ?
Le Q-learning a été introduit par Christopher Watkins en 1989 comme un algorithme d’apprentissage par renforcement. Cet algorithme permet à un agent d’apprendre la valeur des actions dans un état donné, en mettant continuellement à jour ses connaissances à travers l’expérience, tout comme le rat dans la boîte de Skinner.
Contrairement aux expériences de Pavlov, où l’apprentissage reposait sur des associations simples, le Q-learning utilise une méthode plus complexe basée sur l’essai et l’erreur. L’agent explore différentes actions et met à jour une table Q qui stocke les valeurs Q, lesquelles représentent les récompenses futures attendues en prenant la meilleure action dans un état spécifique.
Le Q-learning s’applique dans divers domaines, comme les systèmes de recommandation (comme ceux utilisés par Netflix ou Spotify), les véhicules autonomes (comme les drones ou robots), et l’optimisation des ressources. Nous allons maintenant explorer comment cette technologie peut être appliquée à la neuroréhabilitation.
Q-learning et NeuronUP
L’un des avantages de NeuronUP est la capacité de personnaliser les activités en fonction des besoins spécifiques de chaque utilisateur. Cependant, personnaliser chaque activité peut être fastidieux en raison du grand nombre de paramètres à ajuster.
Le Q-learning permet d’automatiser ce processus en ajustant les paramètres en fonction des performances de l’utilisateur dans les différentes activités. Cela garantit que les exercices sont à la fois exigeants et réalisables, améliorant ainsi l’efficacité et la motivation au cours de la rééducation.
Comment ça fonctionne ?
Dans ce contexte, l’agent, que l’on peut comparer à un utilisateur interagissant avec une activité, apprend à prendre des décisions optimales dans différentes situations pour réussir correctement l’activité.
Le Q-learning permet à l’agent d’expérimenter différentes actions en interagissant avec son environnement, recevant des récompenses ou des pénalités, et en mettant à jour une table Q qui stocke ces valeurs Q. Ces valeurs représentent les récompenses futures attendues en prenant la meilleure action dans un état spécifique.
La règle de mise à jour du Q-learning est la suivante :

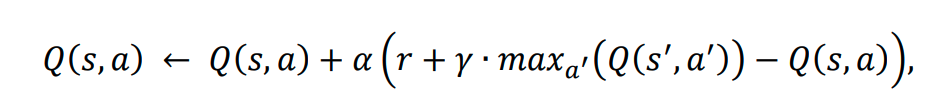
Donde:
𝛂 – est le taux d’apprentissage.
r – est la récompense reçue après avoir effectué l’action a depuis l’état s.
𝛄 – est le facteur d’actualisation, qui représente l’importance des récompenses futures.
s’ – est l’état suivant.



Abonnez-vous
à notre
Newsletter
Exemple d’application dans une activité de NeuronUP
Prenons l’activité de NeuronUP appelée « Images mélangées », qui développe des compétences telles que la planification, les praxies visuo-constructives et la relation spatiale. Dans cette activité, l’objectif est de résoudre un puzzle qui a été mélangé et découpé en pièces.

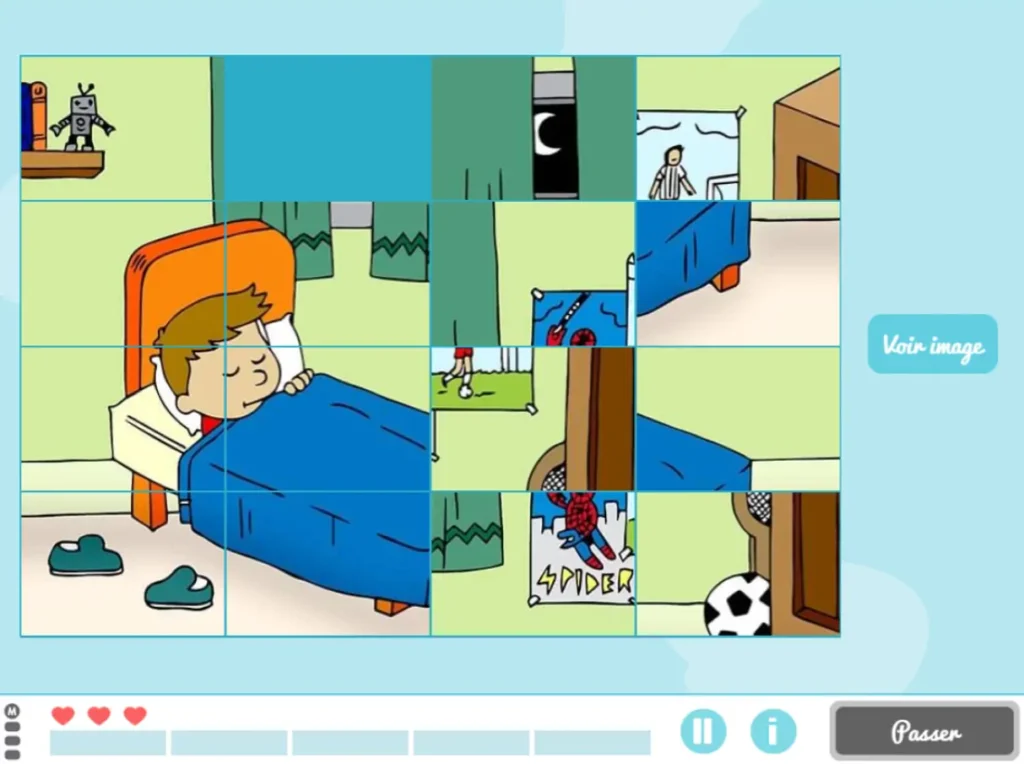
Les variables qui définissent la difficulté de cette activité sont la taille de la matrice (le nombre de lignes et de colonnes), ainsi que le niveau de désordre des pièces (bas, moyen, élevé ou très élevé).
Pour entraîner l’agent à résoudre le puzzle, une matrice de récompenses a été créée en fonction du nombre minimum de mouvements nécessaires pour le résoudre, défini par la formule suivante :

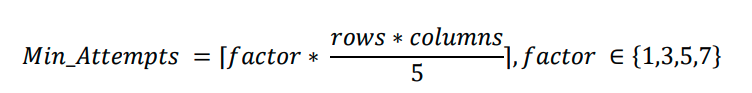
La variable factor dépend de la variable de désordre. Une fois la matrice créée, un algorithme de Q-learning a été appliqué pour entraîner l’agent à résoudre automatiquement le puzzle.
Cette intégration inclut :
Récupération de la valeur Q : La fonction récupère la valeur Q pour un couple état-action dans la table Q. Si ce couple état-action n’a pas encore été entraîné, la fonction retourne 0. Cette fonction cherche la récompense attendue lorsqu’une action spécifique est effectuée dans un état particulier.
Mise à jour de la valeur Q : La fonction met à jour la valeur Q pour un couple état-action en fonction de la récompense reçue et de la valeur Q maximale de l’état suivant. Cette fonction applique la règle de mise à jour du Q-learning mentionnée plus tôt.
Prise de décision concernant l’action à entreprendre : La fonction décide de l’action à prendre dans un état donné, en utilisant une stratégie epsilon-greedy. Cette stratégie équilibre l’exploration et l’exploitation :
- Exploration : Cela consiste à sélectionner la meilleure action connue à ce moment-là. Avec une probabilité ε (taux d’exploration, une valeur entre 0 et 1 qui détermine la probabilité d’explorer de nouvelles actions plutôt que d’exploiter les actions connues), une action aléatoire est choisie, permettant à l’agent de découvrir potentiellement de meilleures actions.
- Exploitation : Cela consiste à tester différentes actions pour découvrir si elles peuvent offrir de meilleures récompenses à l’avenir. Avec une probabilité de 1−ε, l’agent sélectionne l’action ayant la plus grande valeur Q pour l’état actuel, en utilisant les connaissances apprises : a’ = argmaxaQ(s,a). Où a’ est l’action qui maximise la fonction Q dans un état s donné. Cela signifie que, pour un état s donné, l’action a ayant la valeur Q la plus élevée est sélectionnée.
Ces fonctions travaillent ensemble pour permettre à l’algorithme de Q-learning de développer une stratégie optimale pour résoudre le puzzle.
Analyse préliminaire de l’exécution de l’algorithme
L’algorithme a été appliqué à un puzzle de matrice 2×3 avec un facteur de difficulté de 1 (faible), correspondant à un nombre minimum d’essais égal à 2. L’algorithme a été exécuté sur le même puzzle 20 fois, en appliquant la même configuration de mélange à chaque occasion et en mettant à jour la table Q après chaque étape. Après 20 exécutions, le puzzle a été mélangé dans une configuration différente et le processus a été répété, pour un total de 2000 itérations. Les paramètres initiaux étaient les suivants :
- Récompense pour la résolution du puzzle : 100 points
- Pénalité pour chaque mouvement : -1 point
À chaque étape, une récompense ou une pénalité supplémentaire était appliquée en fonction du nombre de pièces correctes, ce qui permettait à l’agent de comprendre ses progrès dans la résolution du puzzle. Cette récompense a été calculée à l’aide de la formule suivante :

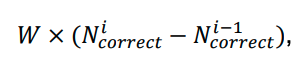
Où :
- W est le facteur de pondération.


Le graphique ci-dessous illustre le nombre de mouvements nécessaires par itération pour que le modèle résolve un puzzle de taille 2×3. Au départ, le modèle a besoin d’un grand nombre de mouvements, ce qui reflète son manque de connaissances sur la manière de résoudre efficacement le puzzle. Cependant, à mesure que l’algorithme de Q-learning s’entraîne, on observe une tendance à la baisse du nombre de mouvements, ce qui suggère que le modèle apprend à optimiser son processus de résolution.
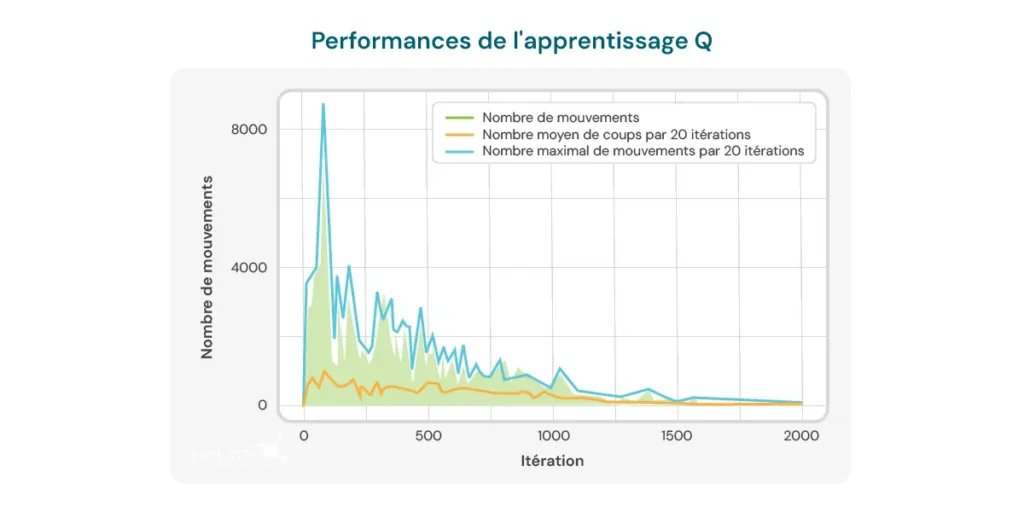


Cette tendance est un signe positif du potentiel de l’algorithme pour s’améliorer avec le temps. Cependant, plusieurs limitations importantes doivent être prises en compte :
- Taille spécifique du puzzle : L’algorithme montre son efficacité principalement pour des puzzles d’une taille spécifique, comme la matrice 2×3. Lorsque la taille ou la complexité du puzzle change, la performance de l’algorithme peut diminuer considérablement.
- Temps de calcul : Lorsque l’algorithme est appliqué à des configurations différentes ou plus complexes, le temps nécessaire pour effectuer les calculs et résoudre le puzzle augmente considérablement. Cela limite son applicabilité dans des situations nécessitant des réponses rapides ou dans des puzzles plus complexes.
- Nombre de mouvements encore élevé : Malgré l’amélioration observée, le nombre de mouvements nécessaires pour résoudre le puzzle reste relativement élevé, même après plusieurs itérations. Lors des dernières exécutions, le modèle nécessite en moyenne entre 8 et 10 mouvements, ce qui indique qu’il y a encore de la place pour améliorer l’efficacité de l’apprentissage.
Ces limitations soulignent la nécessité d’un affinement supplémentaire de l’algorithme, que ce soit en ajustant les paramètres d’apprentissage, en améliorant la structure du modèle ou en intégrant des techniques complémentaires pour permettre un apprentissage plus efficace et adaptable à différentes configurations de puzzles. Malgré ces limitations, il est important de considérer les avantages que le Q-learning offre dans la neuroréhabilitation :
- Personnalisation dynamique des activités : Le Q-learning est capable d’ajuster automatiquement les paramètres des activités thérapeutiques en fonction des performances individuelles de l’utilisateur. Cela permet de personnaliser les activités en temps réel, garantissant que chaque utilisateur travaille à un niveau qui soit à la fois stimulant et atteignable. Cela est particulièrement utile en neuroréhabilitation, où les capacités des utilisateurs peuvent varier considérablement et évoluer avec le temps.
- Augmentation de la motivation et de l’engagement : En adaptant constamment les activités au niveau de compétence de l’utilisateur, on évite la frustration due à des tâches trop difficiles ou l’ennui causé par des tâches trop simples. Cela peut considérablement augmenter la motivation de l’utilisateur et son engagement envers le programme de réhabilitation, ce qui est crucial pour obtenir des résultats réussis.
- Optimisation du processus d’apprentissage : En utilisant le Q-learning, le système peut apprendre des interactions antérieures de l’utilisateur avec les activités, optimisant ainsi le processus d’apprentissage et de réhabilitation. Cela permet de rendre les exercices plus efficaces, en se concentrant sur les domaines où l’utilisateur a besoin de plus d’attention et en réduisant le temps nécessaire pour atteindre les objectifs thérapeutiques.
- Efficacité dans la prise de décisions cliniques : Les professionnels peuvent bénéficier du Q-learning en obtenant des recommandations basées sur des données pour ajuster les thérapies. Cela facilite une prise de décision clinique plus informée et précise, améliorant ainsi la qualité des soins fournis à l’utilisateur.
- Amélioration continue : Au fil du temps, le système basé sur le Q-learning peut améliorer ses performances grâce à l’accumulation de données et d’expérience de l’utilisateur. Cela signifie que plus le système est utilisé, plus il devient efficace dans la personnalisation et l’optimisation des exercices, offrant ainsi un avantage à long terme dans le processus de neuroréhabilitation.
En conclusion, le Q-learning a évolué depuis ses racines en psychologie comportementale pour devenir un outil puissant en intelligence artificielle et neuroréhabilitation. Sa capacité à adapter les activités de manière autonome en fait une ressource précieuse pour améliorer l’efficacité des thérapies de réhabilitation, bien qu’il reste des défis à surmonter pour optimiser complètement son application.
Bibliographie
- Bermejo Fernández, E. (2017). Aplicación de algoritmos de reinforcement learning a juegos.
- Giró Gràcia, X., & Sancho Gil, J. M. (2022). La Inteligencia Artificial en la educación: Big data, cajas negras y solucionismo tecnológico.
- Meyn, S. (2023). Stability of Q-learning through design and optimism. arXiv preprint arXiv:2307.02632.
- Morinigo, C., & Fenner, I. (2021). Teorías del aprendizaje. Minerva Magazine of Science, 9(2), 1-36.
- M.-V. Aponte, G. Levieux y S. Natkin. (2009). Measuring the level of difficulty in single player video games. Entertainment Computing.
- P. Jan L., H. Bruce D., P. Shashank, B. Corinne J., & M. Andrew P. (2019). The Effect of Adaptive Difficulty Adjustment on the Effectiveness of a Game to Develop Executive Function Skills for Learners of Different Ages. Cognitive Development, pp. 49, 56–67.
- R. Anna N., Z. Matei & G. Thomas L. Optimally Designing Games for Cognitive Science Research. Computer Science Division and Department of Psychology, University of California, Berkeley.
- Toledo Sánchez, M. (2024). Aplicaciones del aprendizaje por refuerzo en videojuegos.






